The next wave of artificial intelligence (AI) adoption is already under way, as AI agents — AI applications that can function independently and execute complex workflows with minimal or limited direct human oversight — are being rolled out across the tech industry.
Unlike a large language model (LLM) or generative AI (genAI) tools, which usually focus on creating content such as text, images, and music, agentic AI is designed to emphasize proactive problem-solving and complex task execution, much as a human would. The key word is “agency,” or software that can act on its own.
AI agents can combine multiple capabilities (such as language understanding, reasoning, decision-making, and planning), and execute actions in a broader context, such as controlling robots, managing workflows, or interacting with APIs. They can even be grouped together, allowing a multi-AI agent system working together to solve tasks in a distributed and collaborative way. (OpenAI unveiled “Swarm,” an experimental multi-agentic framework last fall.)
Agents can also use LLMs as part of its decision-making or interaction strategy. For example, while the OpenAI’s LLM-based ChatGPT can generate a poem, or Google’s BERT can classify sentiment in a sentence, an AI agent such as Siri or Alexa can be used to control smart devices and set reminders.
Benjamin Lee, a professor of engineering and computer science at the University of Pennsylvania, said agentic AI is poised to represent a ”paradigm shift.” That’s because the agents could boost productivity by enabling humans to delegate large jobs to an agent instead of individual tasks.
Specialized models could compute answers with fewer calculations and less energy, with agents efficiently choosing the right model for each task — a challenge for humans today, according to Lee.
“Research in artificial intelligence has, until recently, focused on training models that perform well on a single task,” Lee said, “but a job is often comprised of many interdependent tasks. With agentic AI, humans no longer provide the AI an individual task but rather provide the AI a job. An intelligent AI will then strategize and determine the set of tasks needed to complete that job.”
According to Capgemini, 82% of organizations plan to adopt AI agents over the next three years, primarily for tasks such as email generation, coding, and data analysis. Similarly, Deloitte predicts that enterprises using AI agents this year will grow their use of the technology by 50% over the next two years.
“Such systems exhibit characteristics traditionally found exclusively in human operators, including decision-making, planning, collaboration, and adapting execution techniques based on inputs, predefined goals, and environmental considerations,” Capgemini explained.
A warning against unsupervised AI
Capgemini also warned that organizations planning to implement AI agents should establish safeguards to ensure transparency and accountability for any AI-driven decisions. That’s because AI agents that use unclean data can introduce errors, inconsistencies, or missing values that make it difficult for the model to make accurate predictions or decisions. If the dataset has missing values for certain features, for instance, the model might incorrectly assume relationships or fail to generalize well to new data.
An agent could also draw data from individuals without consent or use data that’s not anonymized properly, potentially exposing personally identifiable information. Large datasets with missing or poorly formatted data can also slow model training and cause it to consume more resources, making it difficult to scale the system.
In addition, while AI agents must also comply with the European Union’s AI Act and similar regulations, innovation will quickly outpace those rules. Businesses must not only ensure compliance but also manage various risks, such as misrepresentation, policy overrides, misinterpretation, and unexpected behavior.
“These risks will influence AI adoption, as companies must assess their risk tolerance and invest in proper monitoring and oversight,” according to a Forrester Research report — “The State Of AI Agents” — published in October.
Matt Coatney, CIO of business law firm Thompson Hine, said his organization is already actively experimenting with agents and agentic systems for both legal and administrative tasks. “However, we are not yet satisfied with their performance and accuracy to consider for real-world workflows quite yet,” he said, adding that the firm is focused on agent use in contract review, billing, budgeting, and business development.
Thompson Hine employs more than 400 attorneys, operates in nine US states and promotes its use of advanced technologies, including AI, in providing legal services.
Coatney stressed that research and development around AI agents is still evolving. Most commercially available tools are either fledgling startups or open-source projects like Autogen (Microsoft). Established players such as Salesforce and ServiceNow highlight AI agents as key features, but the term “agent” remains loosely defined and is often overused in marketing, he said.
For example, Salesforce Einstein is designed to enhance customer relationship management using predictive analytics and automation. And Auto-GPT enables users to create an autonomous assistant to complete complex tasks by analyzing a text prompt with GPT-4 and GPT-4o then breaking the goal into manageable subtasks.
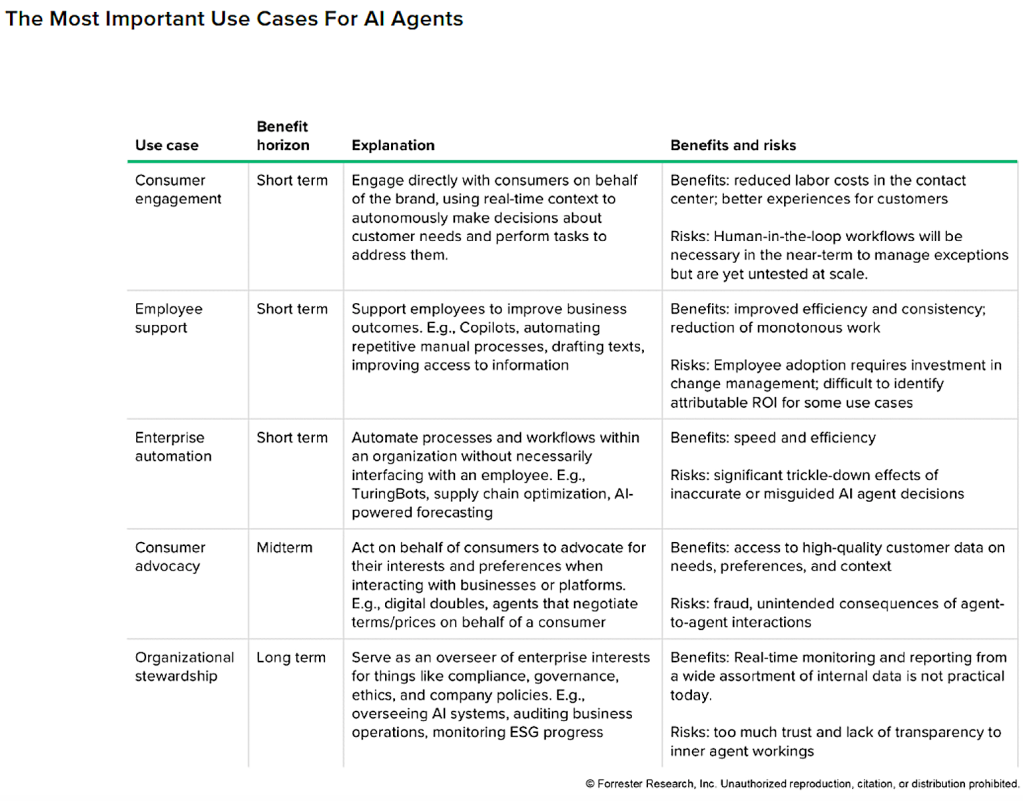
Forrester Research
“AI agents are still largely experimental, but looking at where enterprises have historically invested in automation is instructive,” Coatney said. “Time-consuming, frequent tasks are ripe for this type of solution: finance, operations, administrative processes, etc. Additionally, AI agents are being explored for tasks where genAI)is specifically strong, such as writing.
“For instance, one could imagine a multi-agent system involving an AI project manager, blog writer, brand manager, editor, and SEO specialist working in concert to automatically create on-brand marketing material,” he said.
“These agents leverage the strengths of multiple paradigms while mitigating risk by using more deterministic techniques when appropriate,” Coatney said. “I am particularly excited about the potential of integrating systems and data both within and beyond the enterprise. I see great potential in unlocking value still largely isolated in departmental and vendor silos.”
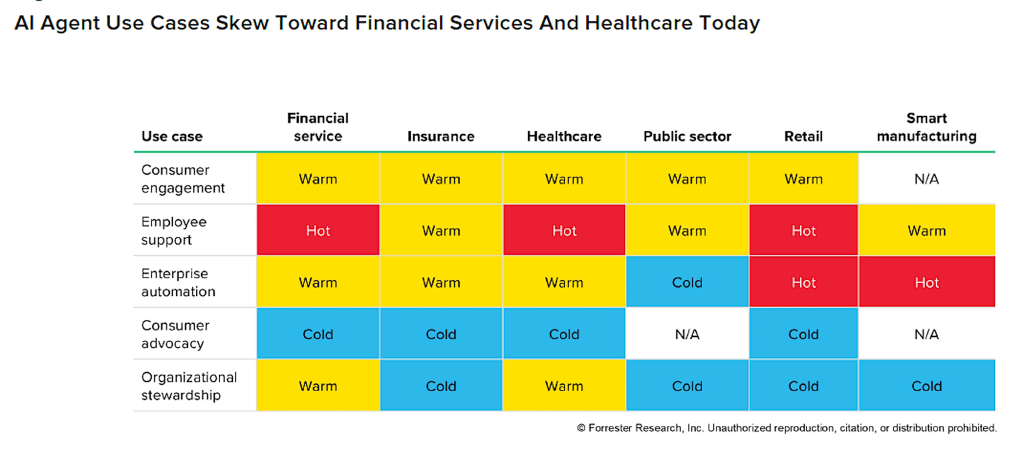
Forrester Research
Limited capabilities today
Tom Coshow, a senior director analyst at Gartner, said many agents today have limited independence, making few decisions and often requiring human review of their actions. Additionally, one of the bigger challenges with deploying agents is ensuring they’re grounded with quality data that produce consistent results, he said.
“AI agents are tricky to deploy and require extensive testing and monitoring,” Coshow said. “The AI agent market is bubbling with startups, the hyper scalers, former RPA [Robotic Process Automation] companies, former conversational AI companies and data and analytics firms.”
Yet, businesses are optimistic about AI broadly, hoping automation will drive efficiency and better business outcomes. Among tech decision-makers who work in services, according to Forrester Research, 70% of businesses expect their organization will increase spending on third-party RPA and automation services in the next 12 months.
Among digital business strategy decision-makers, 92% say that their firm is investing in chatbots or plans to do so in the next two years; 89% said the same about Autonomy, Will, and Agency technology — the three main facets that allow AI agents to act with varying levels of independence and intentionality.
“Businesses must navigate a convoluted landscape of standalone solutions with piecemeal applications lacking an overarching framework for effective coordination or orchestration,” Forrester explained in a September report, “AI Agents: The Good, The Bad, And The Ugly.”
The challenge is that AI agents must both make decisions and execute processes, which requires integrating automation tools like iPaaS and RPA with AI’s flexible decision-making, Forrester said.
Last year, companies such as Salesforce, ServiceNow, Microsoft, and Workday introduced AI agents to streamline tasks such as recruiting, contacting sales leads, creating marketing content, and managing IT.
At Johnson & Johnson, AI agents now assist in drug discovery by optimizing chemical synthesis, including determining the best timing for solvent switches to crystallize molecules into drugs. While effective, the company remains cautious about potential risks, like biased outputs or errors, according to CIO Jim Swanson.
“Like other cutting-edge AI solutions, agents require significant technical and process expertise to effectively deploy,” Thompson Hine’s Coatney said. “Since they are so new and experimental, the jury is still out as to whether the increased value is worth the complexity of setting them up and thoroughly testing them. ROI, as it always has been, is highly project dependent.”