PC sales certainly weren’t going gangbusters in 2024: They only grew a paltry 1% over 2023.
According to new figures from IDC, vendors shipped 262.7 million PCs in 2024. But things did pick up a bit in Q4 2024: Shipments grew 1.8% over the prior year, reaching 68.9 million.
While all this may seem like a modest gain, it still represents progress in a time of economic instability, fear of inflation, geopolitical tensions, and the upcoming US regime change.
“1% growth is actually a pretty good thing in the PC industry right now,” Ryan Reith, group vice president, IDC’s Worldwide Device Trackers, told Computerworld. “That’s what we expected for the year, and actually, the market is shifting back to some recovery.”
The year of refresh
2025 will likely see bigger numbers. IDG expects 4.3% growth in total PC shipments in the coming year. This will largely be due to commercial refreshes that occur even in the “toughest of macro-economic times,” Reith pointed out. Typically, medium-to-large sized companies update their PCs at least every three to four years.
“The commercial refresh usually is pretty resilient because, certainly in developed markets, a lot of medium to large enterprises want to stay ahead,” said Reith.
Indeed, Microsoft has declared 2025 the “year of the Windows 11 PC refresh,” as the tech giant is ending feature and security support for Windows 10 PCs beginning October 14.
However, many factors remain uncertain, including fears of inflation, ongoing geopolitical disputes, and big changes expected with the impending Trump administration. The Consumer Technology Association, for one, estimates that Trump’s proposed steep tariffs on imports — ranging from 10 to 20% for most countries and climbing as high as 100% from China — could increase laptop and tablet prices by as much as 68%.
What about AI PCs?
There has been a ton of hype around AI PCs, as they are set to fundamentally change the way people interact with devices. For instance, built-in AI can perform certain tasks such as information retrieval, while more advanced AI agents can even take autonomous action, leading to significant productivity gains.
Gartner, for instance, has projected that AI PCs will account for 43% of all PCs in 2025. The firm’s analysts estimate that worldwide shipments of AI PCs will total 114 million units this year, representing an increase of more than 165% over 2024. Further, the firm predicts that by 2026, AI laptops will be the only choice of laptop available to large enterprises (compared to less than 5% availability in 2023).
Big tech is certainly betting on this trend. Microsoft, for its part, introduced Copilot+ PCs in May, and Nvidia introduced its AI PC Project Digits this week at CES. Qualcomm and Advanced Micro Devices (AMD) have unveiled their own AI processors and Dell is working on AI hardware, too.
“This is a huge leap of technology, from every aspect of software down to the hardware and everything in between,” said Reith. “This is going to be a fundamental change, in a positive way, in the industry.”
More advanced PCs that can do more than other PCs (and humans, too) might eventually translate to less hardware shipped, he noted. However, it will be a net positive. “There’s going to be a lot of revenue gains from that, from the software side, cloud side, everything else.”
Not so fast…
Still, Reith noted, the industry has gotten a little ahead of itself when it comes to AI PCs. While they someday will become the norm — all modern laptops and desktops, after all, contain some sort of AI — that’s more of a long-term trend.
This is notably because “budgets are constrained across the board,” said Reith. “It doesn’t matter if you’re a tech company, healthcare, whatever. When AI comes up, it’s, ‘Look, how much extra is that going to cost?’ It’s all about the dollar.”
Also, while they’re innovating at an impressive clip, big tech companies haven’t really lived up to the hype, he pointed out. Industry watchers, for instance, thought Microsoft would deliver more around Copilot+, providing concrete use cases through its partnerships and illustrating how enterprises can get returns on their investments.
“Microsoft didn’t deliver, but it didn’t fall on its face,” said Reith. “Even if you under-deliver a little bit in a time when budgets are constrained, it puts a bigger spotlight on, ‘Hey, maybe we can wait a little bit.’”
There are still very, very good PCs out there
IT decision makers don’t need to feel rushed to purchase AI PCs, Reith noted. Don’t rule out PCs the next level down, he advised; there are still “really, really good” products from PC vendors that run Intel’s Meteor Lake processors (introduced in 2023) or AMD chips, among others.
“So don’t feel like you’re buying down,” said Reith. “We have a lot of very, very good PCs; they’re just not the ones that are the latest and greatest and cost 50% more.”
Also, he pointed out, while Microsoft is sunsetting Windows 10, enterprises still have access to an affordable service support extension. “It’s a very, very attractive option, especially right now, if you’ve got good hardware.”
The AI PC buzz is real
Recognizing the dampening of interest (at least for now) in AI PCs, suppliers like Lenovo, HP, Dell, and others are already adjusting and shifting their focus to PCs the next level down in their portfolio, said Reith.
“It’s going to pick up, they’ve kind of paused a little bit on the supply side,” he said. However, “they’re not going to slow down the innovation.” In fact, “they’re innovating like crazy.”
Ultimately, “the buzz is real,” he said. “I think everyone got a little over their heads on the immediate opportunity. It’s just going to be a little bit more prolonged.”
Researchers at Google Deepmind and Stanford University have concluded that a two-hour interview is sufficient to create a realistic AI copy with the same personality as the interviewee.
In an experiment, 1,052 people were interviewed using a questionnaire that addressed everything from personal life events to opinions about society. A digital AI copy was then created and when a new round of questions was asked, it answered the same as its human counterpart in 85% of cases.
Apple has vehemently denied that it ever abused recordings of Siri requests by using those records for marketing, ad sales, or any of the other creepy nonsense we’re being forced to tolerate with other connected devices.
The company’s denial follows a recent $95 million settlement concerning a widely reported sequence of events when it became known that the company had human contractors grading people’s spoken Siri requests. Many of us were extremely shocked at the nature what was being recorded and shared with those contractors, and to be fair, Apple swiftly took steps to remedy the situation, which it said was necessary to improve Siri’s accuracy.
The plaintiffs claimed that Apple’s systems had been used to trigger ads targeted at them, which Apple denied despite having settled the case. It’s thought the company chose to settle because it wanted to prevent further accusations against its commitments to privacy.
An unforced error with big consequences
The company has always denied that it abused the Siri request records in any way and has constantly pointed out that the recordings were not directly connected to any individual user, which is very unlike the experience you get with other connected devices. That denial wasn’t enough in this case.
That’s because devices that lack Apple’s commitment to privacy are the ones responsible for ads you might encounter that spookily reflect private conversations you may have had. Apple says its systems don’t do that.
In a statement following the resolution of the lawsuit, an Apple spokesperson said: “Apple has never used Siri data to build marketing profiles, never made it available for advertising, and never sold it to anyone for any purpose. Privacy is a foundational part of the design process, driven by principles that include data minimization, on-device intelligence, transparency and control, and strong security protections that work together to provide users with incredible experiences and peace of mind.”
Apple’s track record is a good one
Apple has committed vast resources to creating privacy protections across its systems. Everything from Lockdown mode to tools to prevent aggressive ad targeting and device fingerprinting represents the extent of its efforts, work that touches almost every part of the company’s ecosystem.
A future looming problem, of course, is that while Apple might be keeping to its pro-privacy promise, not every third-party developer likely shares the same commitment, despite the Privacy Labelling scheme the company has in place at the App Store.
This might become an even bigger problem as Apple is forced to open up to third-party stores. It seems plausible to expect some popular apps sold via those stores might choose to gather user data for profit.
With that monster visible on the horizon, Apple has also confirmed that it has teams working to build new technologies that will enhance Siri’s privacy. It also said, “Apple does not retain audio recordings of Siri interactions unless users explicitly opt in to help improve Siri, and even then, the recordings are used solely for that purpose.”
How Apple already protects Siri privacy
Apple pointed to several protections it already has in place for Siri requests:
Siri is designed to do as much processing as possible right on a user’s device — though some requests require external help, many, such as search suggestions, do not.
Siri searches and requests are not associated with your Apple Account.
Apple does not retain audio recordings of Siri interactions unless users explicitly opt in to help improve Siri.
Apple has another protection it is putting into place: Private Cloud Compute. This will mean that Apple Intelligence requests made through Siri are directed to Apple’s cloud servers, which offer industry-leading security. “When Siri uses Private Cloud Compute, a user’s data is not stored or made accessible to Apple, and Private Cloud Compute only uses their data to fulfil the request,” the company said.
To some degree, the need to make these statements is a problem Apple foolishly created for itself in the way it initially handled Siri request grading. The manner in which that was done tarnished its reputation for privacy, which is unfortunate given the company knows very well that in the current environment digital privacy is something that must be fought for.
There is a silver lining to the clouded sky. That Apple is now making these statements means it can once again raise privacy as a consideration as we move through the next chapters of AI-driven digital transformation.
Recently, I was asked a question I haven’t heard in several years: Can you manage Apple devices without using MDM?
The technical answer is yes. You can use configuration profiles and Apple Configurator to do this.
But you really shouldn’t try that approach. With mobile device management (MDM) vendors licensing their software for as little as $1 per device or user per month, MDM should be the go-to option for all but those on the tiniest of shoestring budgets. (There’s also the possibility of using Apple Business Essentials, a stripped down solution from Apple intended for small organizations.)
MDM and Apple Business Manager (or Apple Business Essentials) allow for zero-touch deployment. IT does not even have to see a device; it can be shipped new in the box to an employee and it will automatically configure and enroll in MDM when querying Apple’s activation servers during startup.
By contrast, managing devices manually can be extremely time consuming because you have to set up each device by hand when installing configuration profiles — and you must touch it every time you need to make changes. Security updates (or any software updates) cannot be forced to install, leaving it up to each user to install them or not.
When a device is managed via MDM, there’s a constant back and forth communication between the device and your company’s MDM service. This allows a whole host of features, particularly security features such as being able to query the device status, lock/unlock the device, install software updates, and add applications and other content over the air.
You also gain the ability to securely separate work and personal use of a device and to make use of managed Apple Accounts rather than relying on a user’s personal Apple account.
Managed Apple Accounts perform the same function as personal Apple IDs, but they’re owned by an organization rather than the end user and they link to an employee’s work-related accounts. They can also be managed in a way that allows users access Continuity features at work and provides a work-related iCloud account. One big advantage here is that work related passwords and passkeys can sync across all of a user’s work devices (and they can be automatically removed from a device if a worker leaves the organization.
Another consideration to keep in mind if you’re a small shop looking to save a few dollars is that you might not always be small. You may not think you need the features that come with MDM solutions, but as your company grows, your needs will change — and you’ll likely have to go through the headache of migrating away from manual management anyway.
This is the part where I tell you to turn back from trying to manage Apple devices manually.
But if you’re truly determined to go it without using MDM or you’re really that cash strapped and you have a small number of employees and devices, here’s what you need to know. (Just don’t say you weren’t warned if you go this route and run into problems or security breaches.)
The basic component for managing devices is the configuration profile; it’s an XML file that specifies the various options you want to set up. These profiles have been around since the iPhone 3G launched in 2008 (two years before MDM even existed). These files also underpin MDM configuration, but you get a much broader selection of configuration options and an easier interface via MDM.
Apple Configurator for Mac is a free tool available in the App Store. There is an iPhone version as well that’s used to enroll devices if they’re not eligible for zero-touch deployment — typically, devices bought outside of a business purchase from Apple or an authorized reseller. (The Mac version can also be used for this purpose.)
The latest version of Apple Configurator supports the management of iPhones, iPads and Apple TVs, but — cautionary alert — it does not support managing Macs. (This is another downside to manual device management.)
Apple Configurator allows you to create a blueprint for various device types and to create configuration profiles with a simple-to-use GUI. You can then assign your profiles to blueprints. Configurator also lets you prepare devices to receive configuration profiles; backup and restore devices; determine whether they will work using Apple’s Supervision functions, which provide some additional control over devices; and to install apps.
Once you’ve set up blueprints and added configuration profiles and apps, you’ll need to connect each device via a USB-to-Lightening cable (for older devices) or with a USB-C cable (for newer devices) and then assign the device to a blueprint. When preparing a device for Apple Configurator, you can choose to remove various steps in Setup Assistant (just as in MDM). You can also set the device name, wallpaper, and home screen layout.
Managing Macs works essentially the same way — by building configuration profiles. But you need to hand install them on each Mac. Depending on the payload of the profile and whether a user has local admin privileges, the Mac user might be able to delete installed configuration profiles. Keep that in mind.
Apple provides a user guide that offers additional details and a walk-through of tasks in Apple Configurator.
So, as I noted from the very start, you can see that it’s certainly possible to manage Apple devices manually. But hopefully, you can also now see that there are too many advantages to managing devices using MDM (or Apple Business Essentials) to do it the old-school way.
From better security to a lighter IT workload and an improved user experience, MDM really can streamline everything needed to keep your fleet of Apple devices up and running.
AlphaSense is a market intelligence platform that uses generative artificial intelligence (genAI) and natural language processing to help organizations find and analyze insights from sources like financial reports, news, earnings calls, and proprietary documents.
The purpose behind the platform is to allow business professionals to access relevant insights and make data-driven decisions.
Sarah Hoffman, director of AI research at AlphaSense, is an IT strategist and futurist. Formerly vice president of AI and Machine Learning Research at Fidelity Investments, Hoffman spoke with Computerworld about how AI will change the future of work and how companies should approach rolling out the fast-moving technology over the next several years.
In particular, she talked about how the arrival of genAI tools in business will allow workers to move away from repetitive jobs and into more creative endeavors — as long as they learn how to use the new tools and even collaborate with them. What will emerge is a “symbiotic” relationship with an increasingly “proactive” technology that will require employees to constantly learn new skills and adapt.
How will AI shape the future of work, in terms of both innovation and new workforce dynamics? “AI can manage repetitive tasks, or even difficult tasks that are specific in nature, while humans can focus on innovative and strategic initiatives that drive revenue growth and improve overall business performance. AI is also much quicker than humans could possibly be, is available 24/7, and can be scaled to handle increasing workloads.
“As AI automates more processes, the role of workers will shift. Jobs focused on repetitive tasks may decline, but new roles will emerge, requiring employees to focus on overseeing AI systems, handling exceptions, and performing creative or strategic functions that AI cannot easily replicate.
“The future workforce will likely collaborate more closely with AI tools. For example, marketers are already using AI to create more personalized content, and coders are leveraging AI-powered code copilots. The workforce will need to adapt to working alongside AI, figuring out how to make the most of human strengths and AI’s capabilities.
“AI can also be a brainstorming partner for professionals, enhancing creativity by generating new ideas and providing insights from vast datasets. Human roles will increasingly focus on strategic thinking, decision-making, and emotional intelligence. AI will act as a tool to enhance human capabilities rather than replace them, leading to a more symbiotic relationship between workers and technology. This transformation will require continuous upskilling and a rethinking of how work is organized and executed.
Why is Gen Z’s adoption of AI a signal for broader trends in business technology? “Gen Z, having grown up in a highly digital environment, is naturally more comfortable with technologies like AI. Their rapid adoption of AI tools highlights a shift towards technology-first thinking. As this generation excels in the workforce, their familiarity with AI will drive its integration into business processes, pushing companies to adopt and adapt to AI-driven solutions more quickly.
“Gen Z’s use of AI also reflects the broader understanding that AI complements human skills rather than replaces them. As businesses increasingly adopt AI, they will need to recognize the importance of training employees to work alongside AI, ensuring that AI becomes a valuable tool that enhances human creativity and strategic thinking.”
Sarah Hoffman
AlphaSense
What is AI’s role in business teams and how can companies best leverage it to enhance human skills and knowledge? “AI’s role in teams is to act as a tool that enhances human capabilities rather than [as] a complete replacement for human decision-making. Professionals can use AI to streamline routine tasks, such as data analysis and trend identification, which frees up time for more strategic and creative work. Additionally, AI can accelerate learning and innovation by synthesizing complex data, identifying new perspectives, and providing personalized insights.
“To best leverage AI to enhance human skills and knowledge, companies should:
Define AI’s role clearly and establish specific tasks for AI, such as data processing or generating insights, and use it as a tool to support human judgment and decision-making.
Regularly check AI’s outputs for accuracy and reliability to ensure its recommendations align with human expertise.
Train teams effectively with the knowledge of when to trust AI’s recommendations and, importantly, when to rely on their own judgment and expertise.
Enable effective collaboration between AI tools and humans. AI should complement human intelligence, helping teams work more efficiently, creatively, and strategically.”
What should companies prioritize to harness AI for long-term success? “Before companies can leverage this powerful technology and the business opportunities that come with it, they must consider the common pitfalls. Companies can build a proprietary system that may be the best fit for their customers or they can leverage third-party partnerships to mitigate the initial cost of building an AI system from the ground up. This is a pivotal decision that impacts future success and longevity. And the answer doesn’t have to be just build or buy; often a hybrid solution can make sense too, depending on the use cases involved.
“Companies should focus on long-term strategy, quality data, clear objectives, and careful integration into existing systems. Start small, scale gradually, and build a dedicated team to implement, manage, and optimize AI solutions. It’s also important to invest in employee training to ensure the workforce is prepared to use AI systems effectively.
“Business leaders also need to understand how their data is organized and scattered across the business. It may take time to reorganize existing data silos and pinpoint the priority datasets. To create or effectively implement well-trained models, businesses need to ensure their data is organized and prioritized correctly.
“It’s crucial to have alignment across teams to create a successful AI program. This includes developers, data analysts and scientists, AI architects and researchers and other critical roles that decide the overall business goals and objectives. These teams must work together closely to ensure there is consistency across development, product, marketing, etc.
“Another critical aspect for companies to consider is the end user. For AI to deliver long-term success, businesses must prioritize understanding the needs and expectations of those who will interact with or benefit from the technology. This involves gathering feedback from end-users throughout the development and implementation process to ensure the solutions being built provide real value.
“By focusing on these priorities, companies can ensure their workforce is prepared and AI programs are highly effective and ethically sound, positioning themselves for long-term success.”
What are some of the biggest advances you see happening with AI this year? “In 2025, generative AI will transition from its experimental phase to mainstream, product-ready applications across industries. Customer service automation, personalized content creation, and knowledge management are expected to lead this evolution.
“As more production-ready solutions are deployed, companies will refine methods to quantify AI’s impact, moving beyond time savings to include metrics like customer satisfaction, revenue growth, enhanced decision-making, and competitive advantage. These advancements will help executives make more informed investment decisions, accelerating generative AI adoption across industries.
“Generative AI systems will also become significantly more proactive, evolving beyond the passive ‘question-and-answer’ model to intelligently anticipate users’ needs. By leveraging a deep understanding of user habits, preferences, and contexts, these systems could predict and provide relevant information, assistance, or actions at the right moment. Acting as intelligent agents, they may even begin autonomously handling simple tasks with minimal input, further enhancing their utility and integration into everyday workflows.”
For what purposes do you see generative AI moving from pilot to production next year? “The leap from pilot projects to full-scale deployment is the next critical step for generative AI in 2025. While 2024 saw companies experiment with AI for efficiency — such as automating customer service queries or creating personalized content — these applications are expected to mature and deliver measurable business outcomes. As companies refine their data pipelines and AI infrastructure, these tools will likely become integral to daily operations rather than isolated experiments.
“Beyond efficiency, there’s a growing interest in leveraging AI for strategic innovation. For example, businesses may use generative AI to prototype new products, model market scenarios, or enhance customer experiences. These strategic applications could reshape industries by fostering innovation, increasing competitive advantage, and driving revenue growth.”
This past year, many organizations seemed to struggle with cleaning their data in order to prepare it for use by AI. Why do you believe that’s still necessary? “Data cleaning remains essential for ensuring AI reliability, even as models become more advanced. Generative AI systems depend on high-quality, consistent data to produce accurate results. Poorly prepared data can lead to biased outputs, reduced performance, and even legal risks in sensitive applications. By standardizing, de-duplicating, and enriching datasets, organizations ensure their AI systems are well-equipped to handle real-world complexity.”
How should companies go about ensuring the responses they get from genAI are accurate? “To ensure the accuracy of generative AI, businesses must employ rigorous testing and validation methods. Models should be evaluated against real-world datasets and specific benchmarks to confirm their reliability.
“Many companies are turning to retrieval-augmented generation (RAG), using domain-specific trusted and citable data to mitigate the risk of misinformation. This approach is particularly critical for applications like healthcare or financial decision-making where errors can have serious consequences. Similarly, in such high stakes functions, human oversight is essential.”
Companies that have deployed AI have used multiple models, but how do you create pipelines between those models and businesses for strategic purposes? “Rather than relying on a single provider, companies are adopting a multi-model approach, often deploying three or more AI models, routing to different models based on the use case. Continuous monitoring is necessary to ensure the models perform optimally, maintain accuracy, and adapt to changing business needs. “
Do you see smaller language models or the more typical large language models dominating in 2025 and why? “In 2025, the choice between smaller language models and large language models will ultimately depend on specific use cases. SLMs are invaluable for specified, narrow tasks that have use-case specific constraints around security, cost and latency. SLMs can be faster and cheaper to operate and can be deeply customized for domain workflows. For example, AlphaSense uses SLMs for earnings call summarization. Another advantage of SLMs is that they can be run on-device, which is critical for many mobile applications leveraging sensitive, personal data.
“LLMs, on the other hand, will dominate in general-purpose and complex applications requiring high-level reasoning, adaptability, and creativity. Their expansive knowledge and versatility make them essential for advanced research, multimodal content generation, and other sophisticated use cases. A hybrid approach will likely define the AI landscape in 2025, combining the efficiency of SLMs with the versatility of LLMs, enabling businesses to optimize performance, cost, and scalability.”
A federal judge in San Francisco has ruled that a privacy lawsuit against Google, alleging the company improperly collected personal data from mobile devices, can proceed.
Chief Judge Richard Seeborg dismissed Google’s argument that it had sufficiently informed users about its Web & App Activity settings and obtained their consent for tracking, paving the way for a possible trial in August.
The lawsuit accuses Google of intercepting and saving browsing histories without user consent, even after tracking settings were disabled.
Judge Seeborg noted that reasonable users could view Google’s data practices as “highly offensive,” given the ambiguity in its disclosures and internal employee concerns about how the settings were communicated.
“Internal Google communications also indicate that Google knew it was being ‘intentionally vague’ about the technical distinction between data collected within a Google account and that which is collected outside of it because the truth ‘could sound alarming to users’,” Seeborg wrote.
The Judge noted that Google defended its practices by downplaying internal employee comments cited in the lawsuit, arguing they were focused on identifying technical improvements rather than raising privacy concerns. The company also said that some employees involved in these discussions lacked familiarity with the Web & App Activity (WAA) settings.
“The concerns raised by Google employees are relevant, however, at the very least for tending to show that the WAA disclosures are subject to multiple interpretations,” Seeborg added. “What is more, the remarks and Google’s internal statements reflect a conscious decision to keep the WAA disclosures vague, which could suggest that Google acted in a highly offensive manner, thereby satisfying the intent element of the tort claim.”
Broader implications of the case
The legal battle against Google could have far-reaching implications for enterprise data governance, particularly in how companies handle user consent and transparency.
The case raises questions about whether current data collection practices align with user expectations and legal requirements, especially in an era where trust in technology firms is under heightened scrutiny.
“Enterprise data policies have typically assumed that vendors are not saving personal information unless there is some sort of opt-in policy,” said Hyoun Park, CEO and chief analyst at Amalgam Insights. “In particular, the argument that data capture ‘doesn’t hurt anyone’ is a red herring compared to the actual requirement for governance.”
However, while Google’s defense focuses on its own practices, the outcome of the case could drive the industry toward better transparency and accountability.
“Google obviously has to defend its actions and perspective, but my hope is that this finding leads to greater transparency,” Park added. “Obviously, one of the challenges of any complex data service, such as Google or Microsoft or Amazon, is the complexity of governance and administration associated with the data environment and the complicity of tracking the data and activity associated with any sort of service.”
The rise of artificial intelligence is adding complexity to data governance and privacy issues.
While the case focuses on the straightforward matter of capturing personal browsing data, the broader challenge lies in managing the tracking and governance of data-related activities, Park added.
Google’s legal woes continue
Google faces mounting legal challenges as scrutiny over its data practices and market dominance intensifies.
In August 2024, a US District Court ruled Google held a monopoly in online search, accusing the tech giant of using its market dominance to stifle competition.
In September, the European Union’s Data Protection Commission opened an inquiry into the company’s use of personal data.
However, analysts say Google may be able to limit reputational damage and bolster its standing with corporate clients with efforts to enhance privacy measures.
“This case underscores the growing scrutiny of Big Tech’s data practices and the increasing demand for transparency,” said Thomas George, president of Cybermedia Research. “How Google and other major tech companies respond to these expectations remains to be seen, as they strive to balance competitiveness with maintaining the trust of users and partners.”
into”It’s about five to twelve minutes to avoid a security fiasco in 2025,” Eset security expert Thorsten Urbanski said, according to Bleeping Computer .
Eset estimates there are around 32 million computers still running Windows 10 in Germany alone, roughly 65% of all devices in the country. Windows 11 runs on 16.5 million devices, corresponding to approximately 33%. According to Statcounter, global figures for Windows 10 and 11 use are similar.
Computers get clogged with digital “stuff” over time, and while we all like to think we’re good at managing all that D-detritus, there’s somehow never quite enough time to clean things up. If you’re new to the Mac, or even if you’ve used an Apple computer for decades, you need to learn these tips to prune the trash. But first, open the Finder item in the Menu and choose “Empty Trash.”
You’d be surprised how many Mac users forget to do so regularly.
Check your storage
Your Mac has a really excellent storage management system that is available in System Settings in the General tab. (This is also available via the Apple menu, About this Mac, More info). Open that tab and then select Storage. Your Mac will have a little think and reward you with a nice graphic that shows you what is taking up most space on your machine.
This information is divided across numerous sections:
Applications
Bin
Books
Documents
iCloud Drive
Mail
Messages
Music
Photos
Podcasts
TV
Other Users & Shared
macOS
System Data
Now that you’ve got a bird’s eye view of your storage, you can begin to get rid of some of the clutter.
Use the Recommendations
Apple has built a system to help you delete some of the most commonly accumulated stuff, which it makes available as Recommendations. These Recommendations usually appear at the top of the list of stored media, just beneath the image in Storage. You will not see these if you have already followed them, but if you do these may include:
Store in iCloud: This stores all your Desktop and Documents files in the cloud and only keeps recent files locally available on your Mac. The too will also store messages, attachments, photos, and videos for you. This maximizes storage space.
Optimize Storage: This tool automatically removes movies and TV shows sourced from Apple from your Mac, though you can still download them again.
Empty Trash automatically: This tool is recommended as it will automatically erase anything that has been in the Trash for over 30-days.
Open your ‘I’s
Take a look at the above and you’ll find that each section has a small I beside it. Tap this and you’ll get more information to help you manage each of those sections. Tap the I icon for Applications, for example, and you’ll find all those you have installed; you should delete all those you no longer use. if you find any software you don’t need, you can select it in this view and hit Delete to get rid of it, freeing up a little space.
It’s good to take a look inside each category, particularly Messages, where you can delete some of these huge attachments you might not realize you have stored on your device.
What about your Downloads folder?
When did you last take a look inside your Downloads folder? Open it now. (Go>Downloads in the menu bar). Most Mac users find they have lots of items stored there, many of which might still be important. You can free up huge quantities of space on your Mac by going through what you have stored in the folder, filing important items in relevant folders on your Mac, and deleting the rest. Of course, the easiest way to review all those items is to view the files as a list using View>As List.
Manage all your largest files
Here’s a way to quickly review all the largest files you have stashed on your Mac. Let’s create a Smart Folder to monitor for larger files.
In the Finder Menu choose New Smart Folder.
A “New Smart Folder” window appears. You’ll see an option to search “This Mac.” Select that.
Look to the left along the row and you’ll see a Save command (which we will use later). You will also see a Plus (+) button. Tap this.
A set of choices comes up. The first defaults to Kind. Tap this to access a drop down menu where you should tap “Other.”
A long list appears; the one you want is File Size, which you should check.
Once you do so, you’ll be able to select it in the drop down list to replace Kind.
In the next item on the row, you’ll get to choose a parameter. I suggest you use “is greater than.”
Two more choices appear in the row; the first lets you set a number — try 100. The second lets you define a size — try MB.
You will immediately see every file on your Mac that is larger than 100MB. You can delete any of these items by control-clicking them and choosing Move to Bin. But be certain not to delete any System files, as doing so may damage your system. In general, it’s a good rule not to delete anything you do not recognize.
Now you have this bird’s eye view into large items on your Mac you can Save it for future use.
Return to the original Row you first looked at, and tap Save.
Give the search a name, such as “Large Files.”
By default, the search saves in Saved Searches, which is as good a place as any.
Also by default, the search can be added to the sidebar — just make sure this option is ticked.
In the future, you’ll find your new “Large Files” search is available to you in Favorites from within the Finder sidebar, making it super easy to swiftly identify any space invaders you still have on your system.
Take a look in Mail
Your email application is full of stuff. All those Mail attachments mount up over the years, and while you need to keep some of them some of the time, you probably don’t need to retain all of them forever. The best practice is to delete attachments in emails you no longer need; you can do this by deleting the message itself or selecting a message and choosing Remove Attachments in the Messages menu.
You can also create a search in Mail that lets you identify emails containing attachments. Try Mailbox>New Smart Mailbox, select “contains attachments” and save. This is a very unsophisticated tool that just makes it easier for you to monitor any emails you might have received that contain attachments, though it still makes for a very manual process. This is actually the problem with Mail: it doesn’t let you easily manage emails containing large attachments. It does let you do one more thing, however, which you should do now: Open Mailbox and choose Erase Junk Mail to get rid of all the junk that has accumulated. You should also select Erase Deleted Items.
Run Onyx or CleanMyMac
There are numerous applications that claim to help you free up and better manage space on your Mac. I like the free Onyx application, which has been my go-to troubleshooting solution for years. But many users also like MacPaw’s CleanMyMac application. What these applications do is make it possible to delete data you can’t easily or safely get to on your Mac, including unwanted database files, bloated logs, and more. Apple says that macOS will automatically clear such data — including temporary database files, interrupted downloads, staged macOS and app updates, Safari website data, and more — when space is needed on your Mac. But some users might prefer to be proactive.
With Onyx, install the software, open Maintenance and select and run the Cleaning options available there.
Using CleanMyMac, run the Cleanup routine, which will scan your Mac to present you with a selection of choices of what to clean.
What both applications do is force the Mac to run tasks it should do automatically.
Delete old user profiles
If you are using a shared Mac it is likely it will also be a managed Mac, in which case the following option might not be available as it may be managed on your behalf by IT. The problem this solves is that each user on a Mac gets its own user profile which contains all the data and documents that relate to that user. That’s fine when everyone is actively using the Mac, but when someone stops using the machine it becomes necessary to delete their profile to free up the space – though they should get the data they need off the Mac before you do.
To delete an unwanted User profile open System Settings>Users & Groups. If you see the word Admin under your name you will be able to follow the rest of these steps, once you click the lock icon and enter the password. Then choose the user you intend to delete and click Delete User by clicking the – (minus) button.
Three options appear:
Save the home folder in a disk image: All the information will be archived for potential restore,
Don’t change the home folder: Everything is left in place and the user can be restored.
Delete the home folder: Everything is deleted.
Before choosing the third option, it’s incredibly important to ensure you have the right to delete the user.
If you have additional suggestions, please let me know.
Industry forces — led by Apple and Google — are pushing for a sharp acceleration of how often website certificates must be updated, but the stated security reason is raising an awful lot of eyebrows.
Website certificates, also known as SSL/TLS certificates, use public-key cryptography to authenticate websites to web browsers. Issued by trusted certification authorities (CAs) that verify the ownership of web addresses, site certificates were originally valid for eight to ten years. That window dropped to five years in 2012 and has gradually stepped down to 398 days today.
The two leading browser makers, among others, have continued to advocate for a much faster update cadence. In 2023, Google called for site certificates that are valid for no more than 90 days, and in late 2024, Apple submitted a proposal to the Certification Authority Browser Forum (CA/Browser Forum) to have certificates expire in 47 days by March 15, 2028. (Different versions of the proposal have referenced 45 days, so it’s often referred to as the 45-day proposal.)
If the CA/Browser Forum adopts Apple’s proposal, IT departments that currently update their company’s site certificates once a year will have to do so approximately every six weeks, an eightfold increase. Even Google’s more modest 90-day proposal would multiply IT’s workload by four. Here’s what companies need to know to prepare.
Why the push for shorter SSL certificate lifespans?
The official reason for speeding up the certificate renewal cycle is to make it far harder for cyberthieves to leverage what are known as orphaned domain names to fuel phishing and other cons to steal data and credentials.
Orphaned domain names come about when an enterprise pays to reserve a variety of domain names and then forgets about them. For example, Nabisco might think up a bunch of names for cereals that it might launch next year — or Pfizer might do the same with various possible drug names — and then eight managerial meetings later, all but two of the names are discarded because those products will not be launching. How often does someone bother to relinquish those no-longer-needed domain names?
Even worse, most domain name registrars have no mechanism to surrender an already-paid-for name. The registrar just tells the company, “Make sure it’s not auto-renewed, and then don’t renew it later.”
When bad guys find those abandoned sites, they can grab them and try and use them for illegal purposes. Therefore, the argument goes, the shorter the timeframe when those site certificates are valid, the less of a security threat it poses. That is one of those arguments that seems entirely reasonable on a whiteboard, but it doesn’t reflect reality in the field.
Shortening the timeframe might lessen those attacks, but only if the timeframe is so short it denies the attackers sufficient time to do their evil. And, some security specialists argue, 47 days is still plenty of time. Therefore, those attacks are unlikely to be materially reduced.
“I don’t think it is going to solve the problem that they think is going to be solved — or at least that they have advertised it is going to solve,” said Jon Nelson, the principal advisory director for security and privacy at the Info-Tech Research Group. “Forty-seven days is a world of time for me as a bad guy to do whatever I want to do with that compromised certificate.”
Himanshu Anand, a researcher at security vendor c/side, agreed: “If a bad actor manages to get their hands on a script, they can still very likely find a buyer for it on the dark web over a period of 45 days.”
That is why Anand is advocating for even more frequent updates. “In seven days, the amount of coordination required to transfer and establish a worthy man-in-the-middle attack would make it a lot tighter and tougher for bad actors.”
But Nelson questions whether expired domain stealing is even a material concern for enterprises today.
“Of all of the people I talk with, I don’t think I have talked with a single one that has had an incident dealing with a compromised certificate,” Nelson said. “This isn’t one of the top ten problems that needs to be solved.”
That opinion is shared by Alex Lanstein, the CTO of security vendor StrikeReady. “I don’t want to say that this is a solution in search of a problem, but abusing website certs — this is a rare problem,” Lanstein said. “The number of times when an attacker has stolen a cert and used it to impersonate a stolen domain” is small.
Getting a handle on faster site certificate updates
Nevertheless, it seems clear that sharply accelerated certificate expiration dates are coming. And that will place a dramatically larger burden on IT departments and almost certainly force them to adopt automation. Indeed, Nelson argues that it’s mostly an effort for vendors to make money by selling their automation tools.
“It’s a cash grab by those tool makers to force people to buy their technology. [IT departments] can handle their PKI [Public Key Infrastructure] internally, and it’s not an especially heavy lift,” Nelson said.
But it becomes a much bigger burden when it has to be done every few months or weeks. In a nutshell, renewing a certificate manually requires the site owner to acquire the updated certificate data from the certification authority and transmit it to the hosting company, but the exact process varies depending on the CA, the specific level of certificate purchased, the rules of the hosting/cloud environment, the location of the host, and numerous other variables. The number of certificates an enterprise must renew ranges widely depending on the nature of the business and other circumstances.
C/side’s Anand predicted that a 45-day update cycle will prove to be “enough of a pain for IT to move away from legacy — read: manual — methods of handling scripts, which would allow for faster handling in the future.”
Automation can either be handled by third parties such as certificate lifecycle management (CLM) vendors, many of which are also CAs and members of the CA/Browser Forum, or it can be created in-house. The third-party approach can be configured numerous ways, but many involve granting that vendor some level of privileged access to enterprise systems — which is something that can be unnerving following the summer 2024 CrowdStrike situation, when a software update by the vendor brought down 8.5 million Windows PCs around the world. Still, that was an extreme example, given that CrowdStrike had access to the most sensitive area of any system: the kernel.
The $12 billion publisher Hearst is likely going to deal with the certificate change by allowing some external automation, but the company will build virtual fences around the automation software to maintain strict control, said Hearst CIO Atti Riazi.
“Larger, more mature organizations have the luxury of resources to place controls around these external entities. And so there can be a more sensible approach to the issue of how much unchecked automation is to exist, along with how much access the third parties are given,” Riazi said. “There will most likely be a proxy model that can be built where a middle ground is accessed from the outside, but the true endpoints are untouched by third parties.”
The certificate problem is not all that different from other technology challenges, she added.
“The issue exemplifies the reality of dealing with risk versus benefit. Organizational maturity, size, and security posture will play great roles in this issue. But the reality of certificates is not going away anytime soon,” Riazi said. “That is similar to saying we should all be at a passwordless stage by this point, but how many entities are truly passwordless yet?”
What happens when a website certificate expires?
There is a partially misleading term often used when discussing certificate expiration. When a site certificate expires, the public-facing part of the site doesn’t literally crash. To the site owner, it can feel like a crash, but it isn’t.
What happens is that there is an immediate plunge in traffic. Some visitors — depending on the security settings of their employer — may be fully blocked from visiting a site that has an expired certificate. For most visitors, though, their browser will simply flag that the certificate has expired and warn them that it’s dangerous to proceed without actually blocking them.
But Tim Callan, chief compliance officer at CLM vendor Sectigo and vice chair elect of the CA/Browser Forum, argues that site visitors “almost never navigate past the roadblock. It’s very foreboding.”
That said, an expired certificate can sometimes deliver true outages, because the certificate is also powering internal server-to-server interactions.
“The majority of certs are not powering human-facing websites; they are indeed powering those server-to-server interactions,” Callan said. “Most of the time, that is what the outage really is: systems stop.” In the worst scenarios, “server A stops talking to server B and you have a cascading failure.”
Either way, an expired certificate means that most site visitors won’t get to the site, so keeping certificates up to date is crucial. With a faster update cadence on the horizon, the time to make new plans for maintaining certificates is now.
All that said, IT departments may have some breathing room. StrikeReady’s Lanstein thinks the certification changes may not come as quickly or be as extreme as those outlined in Apple’s recent proposal.
“There is zero chance the 45 days will happen” by 2028, he said. “Google has been threatening to do the six-month thing for like five years. They will preannounce that they’re going to do something, and then in 2026, I guarantee that they will delay it. Not indefinitely, though.”
C/side’s Anand also noted that, for many enterprises, the certificate-maintenance process is multiple steps removed.
“Most modern public-facing platforms operate behind proxies such as Cloudflare, Fastly, or Akamai, or use front-end hosting providers like Netlify, Firebase, and Shopify,” Anand said. “Alternatively, many host on cloud platforms like AWS [Amazon Web Services], [Microsoft] Azure, or GCP [Google Cloud Platform], all of which offer automated certificate management. As a result, modern solutions significantly reduce or eliminate the manual effort required by IT teams.”
Want to free up space on your computer? With the right tools, you can quickly eliminate gigabytes of unnecessary files and get back to work — or whatever else you use your computer for.
I’ve long argued you don’t need a “PC cleaner” app. You mostly just need the tools built right into Windows. They’ll do the job, whether you’re using a workplace PC or a home computer.
But I do have some useful free downloads to recommend that might speed things up.
First things first: The classic “Disk Cleanup” tool built into Windows is still the quickest way to free up space. If your PC recently installed a big Windows update, you might be surprised to see that this tool can free up more than 10GB of storage space in just a few clicks.
To launch it, open the Start menu, search for “Disk Cleanup,” and click the “Disk Cleanup” shortcut.
When it opens, select your C: drive, and click “OK.” After it finishes a quick scan, click the “Clean up system files” button and select your C: drive once again.
You’ll see how much space you can free up here. Look through the list and check whatever you want to remove.
You generally shouldn’t run into any issues with removing most of this stuff. However, watch out for the “Recycle Bin” option — if you check this, Windows will empty your Recycle Bin, and you won’t be able to recover files in it. Also, watch out for the “Previous Windows installations” option. If you see this option here and check it, you’ll free up space — but you won’t be able to “roll back” to the previous Windows update if you ever experience a problem.
When you’re done, click “OK” — and you’ll see a good chunk of space used by temporary files and other clutter freed up for other use instantly.
The Disk Cleanup tool can often free up gigabytes of space in a few clicks.
Chris Hoffman, IDG
Windows space-freeing step #2: Think big
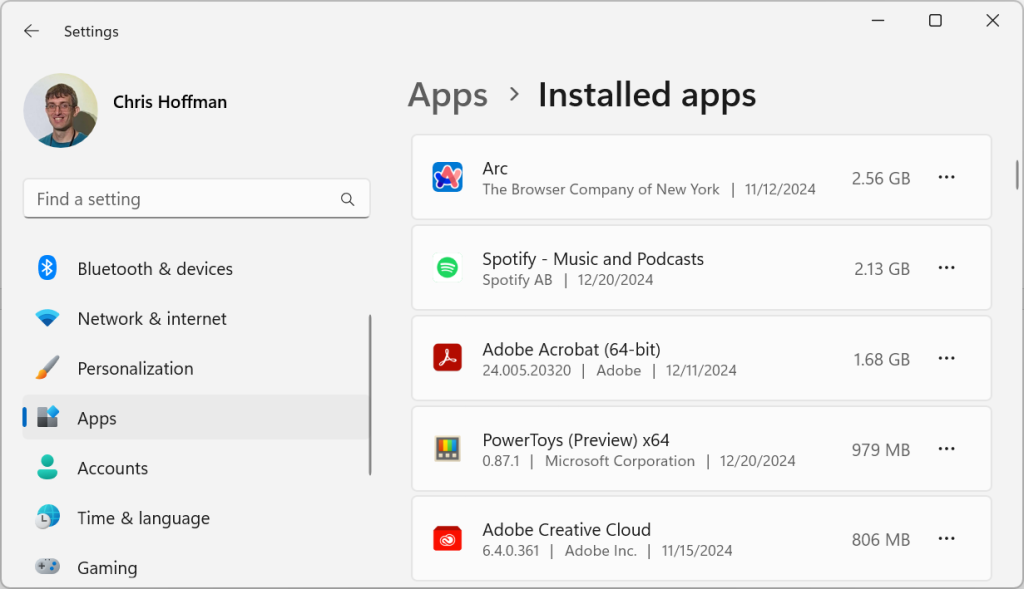
Some programs use quite a bit of space, without any of your own data even playing into the picture. To see just how much each installed application is using, open the Windows Settings app and select Apps > Installed Apps (on Windows 11) or Apps (on Windows 10.)
Tell Windows to sort the apps by “Size,” and it will show you the largest applications at the top of the list. You can uninstall applications from here to free up space.
Bear in mind that this isn’t perfect, though. Many applications don’t show storage space here at all — they’ll have a blank entry in the storage column, even though they may be using lots of space. But it’s still a smart place to start getting a general idea of what’s eating up space and where you can turn to free up precious room.
The storage space numbers in the Apps window aren’t always accurate, but they’re a good place to start.
Chris Hoffman, IDG
Windows space-freeing step #3: Lean on WizTree
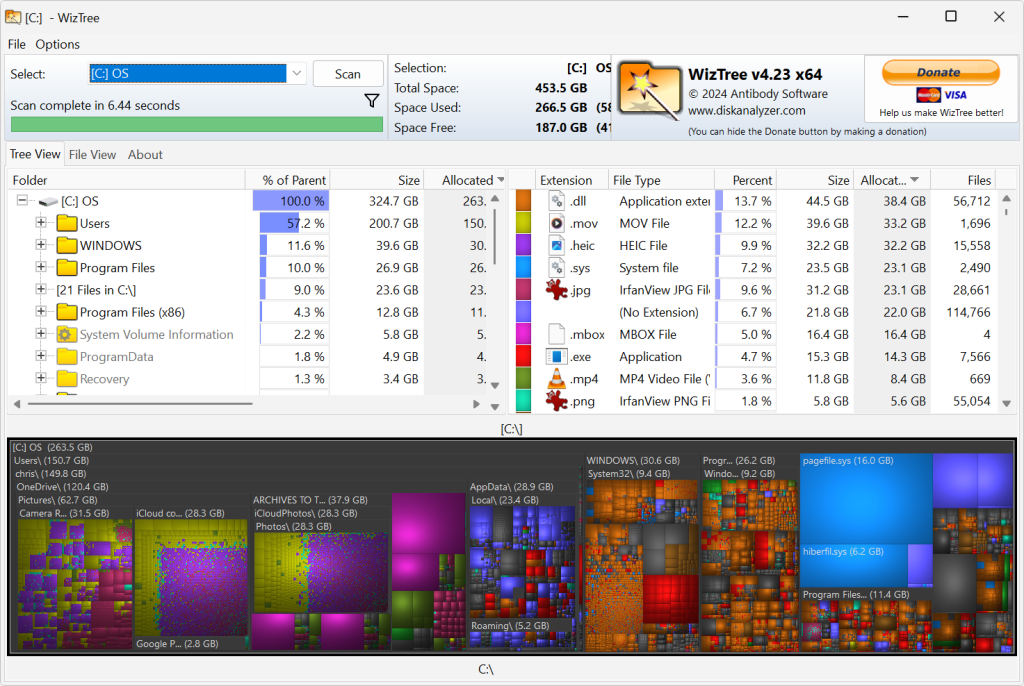
With temporary files cleaned up and a few big applications uninstalled, the next best way to free up space is to see what’s actually using it. I recommend using a free application called WizTree. It’ll give you an overall “bird’s eye view” of exactly what’s using space on your computer.
Install WizTree, launch it, and click “Scan.” WizTree is very fast at scanning your drive — faster than other tools I’ve used and recommended in the past, including the classic WinDirStat.
Just be ready: WizTree will give you a lot of information. Use the visual view at the bottom of the window, though, and you can mouse over areas and see which folders and files are taking up the most room. Perhaps you’ll find an old backup folder you don’t need, or you could discover some apps are using more space than you expect.
From there, you can make informed decisions about which files to move off your computer and which programs to uninstall.
A disk space analyzer is a must-have Windows PC utility.
Chris Hoffman, IDG
Windows space-freeing step #4: Turn to the cloud
There’s a good chance you have a lot of files in cloud file storage services like OneDrive, Google Drive, Dropbox, or iCloud Drive. That’s especially true with OneDrive, as OneDrive is built right into Windows, and you get 1TB of cloud storage if you pay for Microsoft 365.
Once you have all that stuff stored safely in such a remote location, there’s a reasonable argument that you no longer need it also taking up space on your own local PC (unless you simply want the redundancy as an extra fail-safe and backup, of course).
You can address this in several ways: First, you can hide certain folders so they don’t sync to your PC. For example, in OneDrive, right-click the OneDrive cloud icon in your system tray, select “Settings,” click the “Account” option, and then click “Choose folders.” You can then uncheck certain folders, and they will never sync to your PC.
OneDrive also downloads files “on demand” as you use them. You can right-click big files in File Explorer and select “Free up space” to save space on your computer. The next time you open that file, OneDrive will automatically redownload it — but it won’t exist in both places and take up room in the meantime.
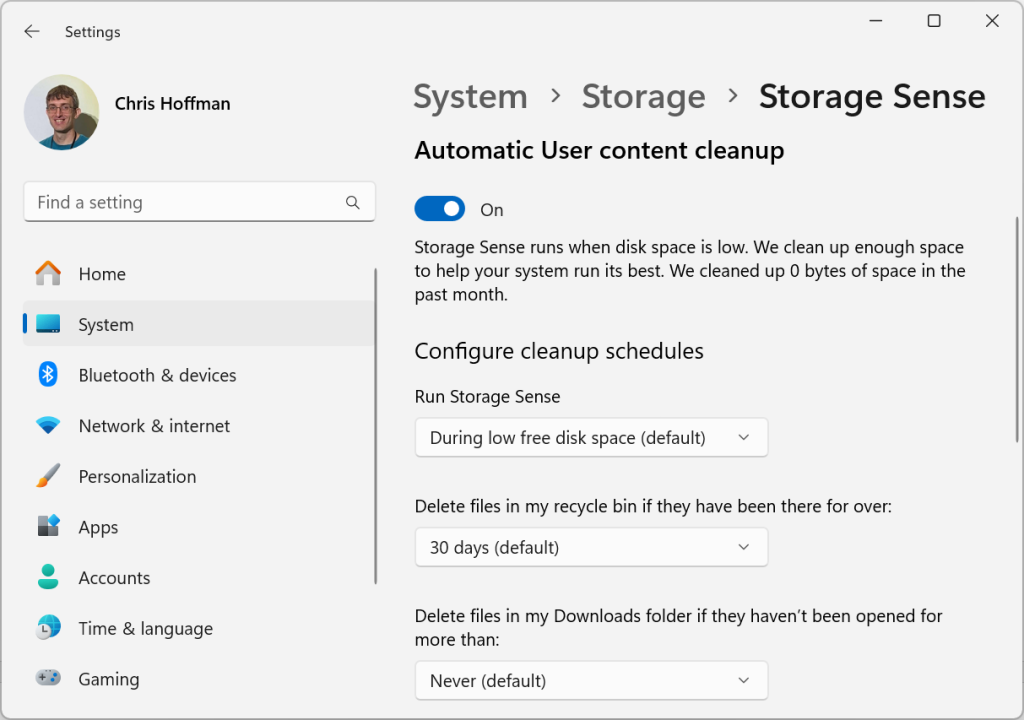
Windows space-freeing step #5: Seek out Storage Sense
On Windows 10 and 11, the “Storage Sense” interface is the more modern replacement for the Disk Cleanup tool. It offers a variety of unique features that can help you free up space.
You find it by opening the Settings app from your Start menu, clicking “System,” and then “Storage.”
Once you do, on Windows 11, you can select the “Cleanup recommendations” option under Storage Management to see things Windows recommends you remove. Beware: Windows will recommend you delete the contents of your Downloads folder! Depending on how you use that folder, you might not want to check that box.
To allow the service to automatically free up space in the background, meanwhile, click the “Storage Sense” option (on Windows 11) or “Configure storage sense or run it now” (on Windows 10). Use the options there to configure how you want Storage Sense to work. For example, you could have Storage Sense automatically empty your Recycle Bin and delete old files in your Downloads folder whenever your PC’s available disk space gets low.
The Storage Sense tool is powerful, but be careful if you use it to empty your Recycle Bin or Downloads folder.
Chris Hoffman, IDG
Windows space-freeing step #6: Delete duplicates
If you suspect you have duplicate files just wasting space on your PC, it’s a good idea to try a duplicate file-finding tool. You can pin down whether you have duplicate files — and exactly where they are.
I recommend using the classic (and free) dupeGuru tool to scan for duplicates. However, there are a variety of good duplicate file finders out there. Once you’ve identified the unnecessarily cloned files, you can decide what to do with them.
Other ways to get more space
If you’re still seeking digital breathing room after all of that, don’t give up! A little creative thinking about your specific setup can help you find more ways to save space.
For example, if you have a modern Copilot+ PC and are using the AI-powered Recall feature, you can control how much space Recall uses for snapshots from Recall’s settings.
If you’ve looked through all of your apps for similar space-saving opportunities and are still coming up short, the final answer is easy: You should consider getting more storage space. Life is too short to spend endless time micromanaging exactly what’s on your computer’s local storage!
On a desktop PC, you could just buy an external storage drive and plug it in — or upgrade the internal storage. Even on a laptop, you might even be able to insert a microSD card for some extra room for files without adding any extra bulk.
Want to make the most of your Windows PC? Sign up for my free Windows Intelligence newsletter. You’ll get three new things to try every Friday and free copies of Paul Thurrott’s Windows Field Guides as a special welcome gift.