Bell launched his lifelogging MyLifeBits project in 1998. The idea was to enter all digital content from one’s life and work. From the project page: He aimed to capture digital versions of “a lifetime’s worth of articles, books, cards, CDs, letters, memos, papers, photos, pictures, presentations, home movies, videotaped lectures, voice recordings, phone calls, IM transcripts, television, and radio.” (Bell famously wore two cameras around his neck, which snapped photographs at regular intervals.) Then, he would use custom-built software to retrieve any fact, any captured idea, any name, any event on demand.
MyLifeBits was part of Bell’s research at Microsoft. He joined Microsoft Research in 1995 and worked there until 2015 when he was named a researcher emeritus.
The death of lifelogging
Eight years ago, I interviewed Bell for Computerworld and, based on what he told me, I proclaimed in the headline: “Lifelogging is dead (for now).” What killed lifelogging, according to Bell, was the smartphone. He stopped his lifelogging experiment when the iPhone shipped in 2007.
Smartphones, he correctly predicted, would gather vastly more data than any previous device could, given their universality and ability to capture not only pictures and user data, but also sensor data. Suddenly, we had access to vastly more data, but no software capable of processing it into a cohesive and usable lifelogging system.
He also correctly predicted that, in the future, lifelogging could return when we had better batteries, cheaper storage and — the pièce de résistance — artificial intelligence (AI) to help capture, organize and present the massive amounts of data. With AI, data doesn’t have to be tagged, filed specifically, or categorized. And it can respond meaningfully with natural language interaction.
At the time, I wrote something I still believe: “I think we’ll find that everybody really does want to do lifelogging. They just don’t want more work, information overload or new data management problems. Once those problems are solved by better hardware and advanced AI, lifelogging and the photographic memory it promises will be just another background feature of every mobile device we use.”
Don’t look now, but we’ve arrived at that moment.
Suddenly: A new wave of lifelogging AI
Bell did his lifelogging research at Microsoft, so it’s especially poignant that within a few days of Bell’s death, Microsoft announced incredible lifelogging tools. (Company execs didn’t use the “L” word, but that’s exactly what they announced.)
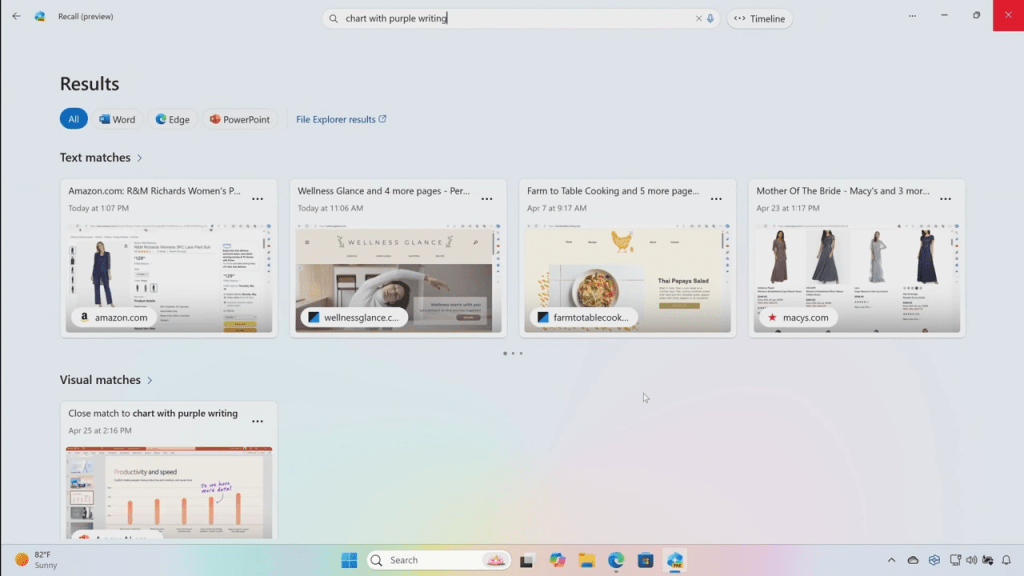
During a special May 20 event preceding the Microsoft Build 2024 conference, the company introduced its Recall feature for Copilot+ PCs, which will run Windows 11 and sport Qualcomm’s new Snapdragon X Elite chips. (They have a neural processing unit (NPU) that makes Recall possible, according to Microsoft.)
Here’s how it works: Recall takes a screenshot of the user’s screen every few seconds. (Users can exempt chosen applications from being captured. Private browsing sessions aren’t captured, either. And specific screenshots, or all captures within a user-designated time frame, can be deleted.)
The screen-grabs are encrypted and stored locally, and the content can then be searched — or the user can scroll through it all chronologically. The secret sauce here, obviously, is that AI is processing all the data, identifying text, context, images and other information from the captures; it can later summarize, recall and generally use your screenshots to answer questions about what you’ve been doing, and with whom. The goal is to provide you with a digital photographic memory of everything that happens on your device.
Microsoft’s Recall feature is lifelogging, pure and simple. AI makes this lifelogging tool feasible at scale for the first time ever.
(Copilot+ PCs start shipping on June 18, 2024, according to Microsoft.)
One week before Microsoft’s announcement, and mere days before Bell’s passing, Google announced lifelogging tools of its own. During a video demonstration of Project Astra, where visual AI identifies and remembers objects in the room and performs other neat tricks via a Pixel phone, the woman showing off the technology picked up AI glasses and continued with her Astra session through the glasses.
Astra is capturing video, which AI can process in real time or refer back to later. It feels like the AI tool is watching, thinking and remembering — which, of course, it isn’t. And it’s trivial for AI to spin out a text log of every single thing it sees, identifying objects and people along the way. AI could then retrieve, summarize, process and help you make instant sense of everything you saw.
Bell wore cameras around his neck to capture snapshots. It couldn’t be more obvious that glasses capturing video to be processed by generative AI is vastly superior for lifelogging.
Google this month also announced another powerful lifelogging tool, which I first told you about in September. It’s called NotebookLM. The AI-enhanced note-taking application beta is free to try if you’re in the United States. The idea is that you take all your notes in the application, and upload all content that comes your way, including text, pictures, audio files, Google Docs and PDFs.
At any point, you can interrogate your own notebook with natural language queries, and the results will come back in a way that will be familiar if you’re a user of the major genAI chatbots. In fact, NotebookLM is built on top of Google’s PaLM 2 and Gemini Pro models.
Like the better chatbots, NotebookLM will follow its display of results with suggested actions and follow-up questions. It will also organize your information for you. You can invite others into specific notes, and collaborate.
NotebookLM is the lifelogging system Gordon Bell spent nine years trying to build. But his ideas were too far ahead of the technology.
The previous two weeks will go down in history as the most momentous thus far in the life of the lifelogging ideas since Vannevar Bush described his Memex concept in 1945. Of course, in the AI era, lifelogging won’t be called lifelogging, and the ability to lifelog effectively will be seen as something of a banality — you know, like the PC and the many other digital gifts midwifed into existence by Gordon Bell.
I told you lifelogging was dead, until we got the AI tools. And now we have them.
Americans, it seems, are of several minds about the hottest of hot topics this year: artificial intelligence. They’re torn between curiosity about the benefits to society and concern about its effects on their lives.
A new study from global consultancy Public First found that, while the most common emotion cited was curiosity (39%), an almost equal number (37%) said they were worried about AI. Last year, 42% cited curiosity and 32% were worried, according to the study, which was based on four nationally representative polls of adults across the US and the UK, and conducted in partnership with the Information Technology & Innovation Foundation’s Center for Data Innovation.
While awareness of AI is growing quickly, day-to-day usage is still quite low, said Jonathan Dupont, partner at Public First, in a webinar about the research. In fact, 51% of Americans said that AI is growing faster than expected, up from 42% in 2023.
ChatGPT, he said, “is now definitely a consumer brand.”
However, people’s emotions are mixed when it comes to concrete benefits for themselves and society, Dupont said: “The lowest thing they rated was actually increasing wages for workers, which suggests they think it might benefit society as a whole, but possibly cause unemployment concerns. They’re less convinced about it translating into actual day to day benefits for ordinary people.”
AI at work
Although only 28% or American workers said they have used an LLM (large language model) chatbot at work, 68% of those who had done so found them helpful or very helpful, and 38% said they have become an essential tool. Overall, this group accounted for 19% of workers.
Age and gender made a big difference: Males aged 18-34 were by far the biggest users at 33%, while only 16% of females in that age group regularly use LLM chatbots at work. Almost half (48%) of workers using LLMs said they had figured out how to use the tools on their own, although this, too, varied by age. Workers under 55 preferred to explore the technology on their own, while those aged 55 or over expressed a desire for formal AI training.
Respondents expected that required job skills will change, according to the study. They saw an increased need for the ability to persuade and inspire people, for critical thinking and problem solving, and for creativity. However, they felt that research, writing well, coding or programming, graphic design, and data analysis will decline in importance with the rise of AI.
Critically, 59% believed it likely that AI will increase unemployment.
But, said Alec Tyson, associate director of research at Pew Research Center, in the workplace, how and where AI is used will affect its acceptance.
“Large majorities would oppose using AI to make a final hiring decision,” he said, an illustration of a broader concern about what’s essentially human. What are humans good for in the areas, whether it’s work or medicine? Your relationship with the primary care doctor that has traditionally been high contact is something close to essentially human; there’s a lot of resistance to using AI to fill those roles. There’s more openness, maybe not outright enthusiasm, but more openness to use AI to help.”
Lee Rainie, director, Imagining the Digital Future Center at Elon University, pointed to two categories of people at the extremes of concerns about AI adoption. “One is creative people themselves,” he said. “I think by instinct they’re innovators in many cases and they’re trying to cut at the edge but I think they see an existential threat more acutely than a lot of other groups here, and watching the legal situation play out, their reactions to AI are going to be very much determined by whether they have autonomy, whether they get paid, what’s disclosed about how the language models are used.”
The second group is people who are suffering in some way. If AI is going to help somebody, he said, there’s not a lot of hesitation about its use.
What jobs can AI automate?
Job loss caused by AI is also a concern. When asked to assign a score from 0 to 10 on how likely respondents felt it was that an AI could do their job as well as they could in the next 20 years, predictions were all over the map. Fully 22% said that robots or AI could not do their job, scoring the prospect at 0. At the other end of the scale, 14% said AI or robots could definitely do their job. In the middle, 14% rated the notion a 5. The average score was 4.7.
The top four occupations at risk, according to respondents, were machine operators (46%), customer service agents (42%), warehouse workers who pick and pack goods (41%), and graphic designers (40%). At the bottom of the list were nurses and care workers, each at 10%.
Overall, however, only 28% thought their jobs would disappear entirely. Others expected they would have other responsibilities (30%), oversee the AI (25%), or spend fewer hours on the job (27%).
Vinous Ali, managing director at Public First, also noted that fears about unemployment vary. “I think the most interesting thing is it’s actually those with degrees, those who are higher and more educated, who feel that their jobs could be at risk, rather than those who have a high school diploma,” she said. “And I think that’s a really interesting difference to previous changes in the workplace.
“I think the top-ranking job that seemed to be highly automated was computer programmer, so this is a real difference, and it’s a real break with the past. And so it’ll be interesting to see how that develops.”
Bottom line
Because AI is so new, there are limitations to the conclusions that can be drawn from the study, Dupont said.
“This is still very much in the abstract for a lot of people, and this is still the future. Polls are always more accurate when you’re asking people about everyday concrete experiences and things they actually are using on a day-to-day basis.
“It’s very easy to push a polling question or make people say, ‘AI is going to be the most amazing thing in the world or AI is going to be terrifying.’ And I think the general picture is, most people have very mixed views, and they don’t know. And it depends how it’s implemented.”
“A poll is a great snapshot in time,” added Ali. “And we’ve worked really hard to make the findings as robust as possible, but clearly, there are limitations when adoption rates are so low, and there are ways that you can work around that. But this is why it’s a tracker poll. … Who knows where we’ll be in a year’s time.”
The complete study is available on the Public First website.
A year ago, GoDaddy didn’t have a single large language model running with its backend systems. Today, the internet domain registry and web hosting firm has more than 50, some of them dedicated to client-side automation products while others are being readied for pilot projects aimed at creating internal efficiencies for employees.
The first of the company’s generative AI initiatives was to build an AI bot that could automate the creation of company design logos, websites, and email and social media campaigns for the small businesses it serves. Then, earlier this year, it launched an AI customer-facing chatbot, GoDaddy Airo. With a culture of experimentation, GoDaddy has moved to formalize the way it documents more than 1,000 AI experiments to help drive innovation. Because “innovation without some kind of hypothesis and some kind of measurement is novelty,” said GoDaddy’s CTO Charles Beadnall.
Beadnall has led the GoDaddy engineering team’s pivot to building AI solutions; he spoke to Computerworld about those efforts, and challenges. The following are excerpts from that interview:
Tell us about your AI journey and how others can learn from your experience. “We’ve been focused on AI for a number of years. We’ve used different variants of it. AI’s a big term and it’s got lots of different subcomponents: machine learning, generative AI, etc. But what we’ve been focused on over the past several years is building out a common data platform across all of our businesses, such that we have inputs coming from our different interfaces and businesses so that we can understand customer behavior better. That’s really enabled us, along with a culture of experimentation, to really leverage generative AI in a way that we can measure the benefits to our customers and to our bottom line, and do that in a way that we continue to iterate against it.
“We’re all about delivering results, ether to our business and our bottom line or to our customers, and so we want to have a measurable hypothesis or what it is that generative AI will deliver to those. That’s something we’ve been building out over the past several years with common data platforms, a culture of experimentation and now leveraging generative AI in practice.”
How important is it to have measurable deliverables with AI deployments? “Ultimately, if you don’t know what it is you’re going to expect to deliver and have some way of measuring it — it may be successful, but you won’t know that it is. It’s been really important for us to have that controlled A/B test, such that we launch a new feature and measure the results against that. So, if you don’t have some form of data you can measure, whether that’s purchase conversion or product activation or something of that nature…, you won’t really know whether they’re having the intended benefit.”
Do you have to create new data lakes or clean up your data repositories before implementing generative AI? I’ve often heard the refrain, garbage in, garbage out. “There is definitely significant implications here. It’s definitely a concern people need to be aware of. The majority of the quality assurance is being performed by the large language model vendors.
“What we’ve done is built a common gateway that talks to all the various large language models on the backend, and currently we support more than 50 different models, whether they’re for images, text or chat, or whatnot. That gateway is really responsible both for implementing the guardrails…, but also to evaluate the responses back from the LLMs to determining if we’re seeing some kind of pattern that we need to be aware of showing it’s not working as intended.
“Obviously, this space is accelerating superfast. A year ago, we had zero LLMs and today we have 50 LLMs. That gives you some indication of just how fast this is moving. Different models will have different attributes and that’s something we’ll have to continue to monitor. But by having that mechanism we can monitor with and control what we send and what we receive, we believe we can better manage that.”
Why do you have 50 LLMs? “This space is moving at a rapid pace with different LLMs leapfrogging each other in cost, accuracy, reliability and security. The large majority of these are in use in sandbox and test environments with only a very small number currently run in production behind Airo. Some of these will be dropped and never make it to production and others will be deprecated as newer models prove more accurate or more cost effective.”
Can you tell me about this gateway. How does it work and did you build it, or did you get it through a vendor? “It’s something we built and it’s going on a year now. We built it to manage the uncertainty of the technology.
“It started out with our initial push into the space as a way to coordinate among the different LLMs. If you think about it logically, a year ago there was one vendor [OpenAI] but it was clear this was going to be a very exciting space. There were going to be a lot of companies that wanted to get into this space, and so we don’t know who’s going to win. And, I think it’s probably a more nuanced discussion of who’s going to win for what. It may be that one model is better for images and another is better for chat. Still another model is better for text. This is going to evolve in such as way that vendors are going to leapfrog each other. So the gateway is a way for us to be somewhat agnostic to the underlying model that we’re using and adapt quickly in changes to cost and changes in accuracy on that path.”
How did you approach training your workforce on AI, and perhaps more importantly, how did you get them to engage with the technology? “I think that’s been surprisingly easy. We had a business unit that came up with our first use case for it, which is helping customers build content for their site and find the right domain name to put on that site. That’s something that a lot of customers get stuck on initially, because it takes a lot of mental cycles to figure out what domain name you’re going to pick, what content you’re going to put on your site — and if you want to start selling product, you have to create descriptions of those items. So, it’s a customer need that we wanted to address.
“Clearly identifying how AI will help us along a path, that business unit really made it a top priority and surged resources against it to come up with some of our first tests within this space. That really did help the team rally behind it to have that clear, compelling use case. We’re running these tests and getting data back and not every experiment was successful. We’re learning things along the way.
“In some ways, experiments that aren’t successful are some of the most interesting ones, because you learn what doesn’t work and that forces you to ask follow-up questions about what will work and to look at things differently. As teams saw the results of these experiments and saw the impact on customers, it’s really engaged them to spend more time with the technology and focus on customer outcomes.”
Is AI ready for creating real-world products you can sell to clients? Or is it more of an assistant, such as suggesting textual content, checking code for errors, or creating video? “We think it’s definitely ready for prime time. Now, it really depends on what the use case is. This is where I think being able to test in a way you can determine [whether it’s] ready for prime time in this particular usage scenario. But it’s definitely adding value to customer interactions, because it’s a set of steps they don’t need to take, but a majority of our customers are leveraging. There are lots of different use cases. Use cases that require deep expertise, it will continue to get better. If the customer wants assistance in completing something more routine…, that’s certainly a prime candidate for leveraging AI.”
What is GoDaddy Airo? What does it do? “It’s basically the AI enablement of our products and services. It’s our underlying AI technology built on top of our data platform, built on top of our experimentation platform and gateway we’re leveraging against our LLMs. Over time, it may turn into additional new products, but right now we’re focused on it making the products we already sell today that much better. It will evolve over time as we experiment our way into it.”
Do your clients use Airo, or do you use it and offer your clients the AI output you receive? “Basically, as soon as you buy a domain name and website, we’ll jump you directly into that experience. We’ll help you build out a site and if you upload inventory items to it, Airo will fill automatically fill that [textual] description for you. If we can get them from having an idea to having a live business online, that’s our major objective. That’s where we’ll be rewarded by our customers. That’s our focus. We do have a metric we track for improving the customer’s value and achievement. It’s still early innings there, but we are improving our customers’ ability to get their businesses up and running.”
How accurate is Airo? “It think it’s reasonably accurate. We run experiments where we have a threshold of accuracy, which is relatively high. We wouldn’t be promoting something that didn’t have significant accuracy and [was] benefiting our customers. I’d say it’s been surprisingly accurate most of the time. Again, there are permutations where we continue to learn over time, but for the core experience, so far, it’s proven to be more accurate than we would have expected.”
Where did you obtain your LLMs that power the generative AI? “The actual LLMs we’re using…are ChatGPT, Anthropic, Gemini, AWS’s Titan. So, we are leveraging a number of different models on the backend to do the genAI itself. But all the integrations into our flows and products is the work we do.”
What are some of the barriers you’ve encountered to implementing AI within your organization, and how did you address them? “We moved quickly but also thoughtfully in terms of understanding the security and privacy ramifications. That’s the area I’d say we spent a reasonable amount of time thinking through. I think the biggest barriers is having the creativity in deciding where these LLMs can be applied and how do you design the experiments to address those needs? Basically, building out the capabilities. That’s where we spend our time today with a common platform approach, which can then account for the security.
“It’s easy to spend enormous amounts of money without much benefit. So it has to be about those factors as well as the customer’s needs. Balancing those factors has been a major focus of ours.”
What’s next? “The big opportunity for us is leveraging AI in more places across the company — internally as well as to make our employee experiences more effective and efficient. There’s a lot of territory for us to cover. We’re under way in all the different avenues now. We’ve got a lot of activity going on to finalize how we augment these LLMs with our own data for more internal use cases. We’re in the thick of it right now. We’re identifying which pilot projects to launch internally.”
In an increasingly digital economy, ransomware might seem unstoppable without security measures in place to proactively detect and prevent it—especially with the relentless cycle of new phishing scams, malware attacks, and cybersecurity threats.
By 2025, Gartner predicts that at least 75% of IT organizations will have experienced at least one ransomware attack; Cybersecurity Ventures echoes this by expecting an average of one ransomware attack on a business every 11 seconds. The dangers of the digital world are relentless; without protection, there is no such thing as secure data. The reality is that ransomware is hard to detect, have long incubation periods, and may have a costly impact on services and business for long periods.
Breaking down anti-ransomware requirements
But what makes a good solution? It should have the right defense systems on the network side, the host side, and the storage side to best optimize data resilience. Protections for these different levels have different priorities, not unlike the relationship between door access controls and coffers.
A good anti-ransomware solution needs to be multilayered, seamlessly integrated, and have clean backup data for optimal recovery. And most of all, given ransomware’s adaptable, ever-shifting nature, good protection must be tailored to the situation at hand, and be able to utilize a range of flexible portfolio solutions.
Leading the industry is Huawei’s Multilayer Ransomware Protection (MRP) Solution. It offers two lines of defense with six layers of protection and is more accurate, more comprehensive, and more lightweight than its predecessor.
The MRP Solution complies with the National Institute of Standards and Technology (NIST) cybersecurity framework for enterprise data resilience, having passed all 21 test cases including detection, blocking, protection, and recovery. In 2024, Huawei’s MRP Solution was the first protection solution of its kind certified by Tolly Group at MWC Barcelona for detecting 100% of ransomware through network-storage collaboration.
Huawei’s MRP Solution is a six-layer systematic system comprising two layers dedicated to networking and the other four to storage: detection and analysis, secure snapshots, backup recovery, and isolation zone protection. Its backup protection uses in-depth parsing to ensure clean data for a strong recovery, with up to 172 TB/h recovery bandwidth. Industry-leading implementation of flash storage and multi-stream backup architecture means significantly faster service recovery and minimal interruptions after detecting malicious encryption. The entire solution has a plug-and-play data card for added flexibility and versatility.
Strong storage protection ensures a strong recovery
One of the key components of a well-integrated ransomware protection solution is a robust storage protection system with multiple fail safes. Where the network is the first layer of security against ransomware, storage is the last line of defense to protect data.
Here, Huawei employs a 3-2-1-1 strategy: three copies of important data, at least two types of storage media, one offsite copy, and one extra copy in the air-gapped isolation zone. The last clean data copy in isolation is used for quick recovery from attacks. Better network-storage collaboration means better proactive defense, including using honeyfiles to attract attackers, and improved recovery speed.
With the growing sophistication of ransomware, businesses can’t afford to underestimate the immediate impact it has on their services—from business outage to data loss—as well as long-term ones such as eroded customer trust and regulatory fines. They must prioritize data resilience and security in an age where data is the backbone of the economy. Huawei offers a world-class ransomware protection solution that paves the way in proactively defending against changing threats, deploys comprehensive storage protection strategies, and spares no effort in the war against malicious actors.
Learn more about how Huawei’s MRP Solution can work for you here.
Once the dust has settled over the next UK election, Apple might be forced to open up its business there in the same way it is being opened up in Europe — thanks to the Digital Markets, Competition and Consumers Bill.
The measure, expected to become UK law later this year, aims to police digital markets, strengthen digital consumer law, control mergers, and set new standards of antitrust. Among other things, this wide-ranging legislation aims to put limits around the big tech firms to increase competition in digital markets.
Apple is likely to be a target
When it comes to Apple, the new law brings in a new status similar to the EU’s “Gatekeeper” role.
The Strategic Market Status (SMS) regime gives the Competition and Markets Authority’s (CMA’s) Digital Markets Unit (DMU) power to designate firms as having SMS if they have “substantial and entrenched market power” and a “position of strategic significance” in relation to digital activities linked to the UK. SMS status will likely be given to Apple along with other major tech firms, including Google, Samsung, Microsoft, who all have market power and strategic significance.
While this could be seen as a badge of honor, it also means the companies will have to follow a code of conduct created by the DMU. “The scope of permitted conduct requirements is incredibly broad, giving the DMU very wide discretion to decide what obligations should be imposed on each firm,” writes Linklaters.
They may also be given more stringent merger reporting requirements and could be subject to what are called Pro-Competitive Interventions (PCI’s).
Forced to open up?
Apple could find itself hit with one or more of these PCIs that might bring the UK more in line with the EU in terms of opening up its platforms and services. This outcome is made more probable because the CMA has been investigating Apple for some time, arguing that, “Apple’s restrictions in particular are holding back potentially disruptive innovation that could transform the way that consumers access and experience content online.”
As previously reported, the three main strands of that investigation relate to:
How control of the browser market affects developers.
The insistence that browser developers use WebKit.
Apple’s refusal to permit cloud gaming services/portals on the App store.
This case has been in and out of courts for a couple of years, but the CMA’s dogged pursuit of this action shows how seriously it intends on taking action.
Now armed with the new legislation, the CMA has more tools at its disposal with which to force Apple and other big tech firms to loosen their perceived grip on digital markets, including things like unbundling WebKit from browsers or opening up for sideloading on devices.
Protecting the core business
Apple’s actions in Europe since similar legislation came into effect shows the company is willing to make changes while working to preserve its business and protect consumer privacy and security. Ultimately, its core mission seems to be that of continuing to offer goods and services via an App Store designed to maintain the user experience and consumer trust that digital storefront has already created.
There is still a compelling argument to say that many consumers actually want a curated, safe, purchasing experience, rather than being exposed to a more complex web of competing stores, with varying commitments to the consumer experience.
However, the international regulatory consensus at this point — including the crazed US antitrust case — seems to be that Apple and other big tech firms must be forced to loosen their grip, the hope being that other competitors can grow in the space they leave behind.
There is some risk to the regulatory approach: In June 2023, Apple said the iOS app economy supports over 4.8 million jobs across the US and Europe. This might turn out to mean something should regulatory zeal dent Apple’s business in those places.
For additional insight into the provisions of the new UK law, you can take a look at the Bill in full here, or explore legal firm Linklater’s commentary on the significance of the Bill here.
Microsoft announced the generative AI-based tool on Monday; it records “snapshots” of a user’s screen every five seconds to provide a searchable log of historic actions going back three months. The feature will be available in preview in new Copilot+ PCs Microsoft and other vendors will begin selling in mid-June.
There are measures in place to protect Recall data, said Microsoft. Recorded data is stored and processed locally and protected with encryption on a user’s device. Users can exclude any apps and websites they want kept private. They can also pause Recall when they want.
However, Recall, which is turned on by default, does not perform “content moderation,” according to Microsoft, which means it won’t conceal confidential information such as passwords or financial account numbers or anything else that might appear on a PC screen.
Microsoft
The ability for Recall to record and store so much sensitive user data is what drew quick criticism over data privacy and security risks.
“I think a built-in keylogger and screenshotter that perfectly captures everything you do on the machine within a certain time frame is a tremendous privacy nightmare for users – and not something I think the average user will actively take advantage of,” said Jeff Pollard, vice president and principal analyst at Forrester.
“My initial thoughts are that it feels like something that could go wrong very quickly,” said John Scott, lead security researcher at security software vendor CultureAI.
It’s the security risks that present the biggest problem, said Douglas McKee, executive director of threat research at network security firm SonicWall. “With the announcement of Microsoft Recall, we are once again reminded of how the advancement of AI and technology features can provide great convenience at the potential cost of security,” he said in a statement. “While many privacy concerns are expressed with Microsoft Recall, the real threat is the potential usage attackers will gain out of this feature.”
McKee said that initial access to a device is easier than other elements of an attack, such as elevation of privileges, “yet with Microsoft Recall, initial access is all that is needed to potentially steal sensitive information such as passwords or company trade secrets.”
Attackers that gain access to a PC running Recall will potentially have access to everything a user has done for around three months, including passwords, online banking details, sensitive messages, medical records, or any other confidential documents.
As a result, Recall could provide a simpler way to steal sensitive data than other tactics such as installing keylogging or screen recording software that might draw more attention. (A Recall icon is placed on the Windows system tray to provide some indication when snapshots are taken, according to Microsoft.)
“Why install keylogging software when I can just switch on something that’s built into the system?” said Scott. “It’s a different way of attacking, but it’s a way that wasn’t there prior to Microsoft saying, ‘We take a screenshot every five seconds,’ and, more importantly, a searchable screenshot every five seconds.”
“Microsoft has taken living off the land to a whole new level with this release,” said Pollard.
Microsoft declined to comment on the security concerns.
Aside from the risk of cyberattack, data privacy concerns have been raised, too. In the UK, the Information Commissioner’s Office — a public body tasked with enforcing data privacy rights — said Wednesday it has written to Microsoft about the Recall feature to “understand the safeguards in place to protect user privacy.”
The amount of data recorded and collected on a user’s PC could be problematic when it comes to compliance with data protection rules. One of the aspects of EU’s GDPR directive is proportionality, said Scott. “You’re building up a huge trove of both your own and other people’s personal data [with Recall] and there doesn’t seem to be a very clear reason [for doing so],” he said.
In addition to a user’s personal information, Recall could collect and store data relating to coworkers, clients, or other third parties. This could happen during a video call, for instance. “If Recall is taking that snapshot every five seconds, have you given me your explicit permission for your images to be recorded with your names? There is enough to be a unique identifier, so there’s a massive problem there.”
And while data is stored locally, there are questions about whether it could also be backed up somewhere else, he said, or even be hosted on Microsoft’s cloud servers in future.
Justin Lam, senior research analyst covering information security at S&P Global Market Intelligence, said that tackling security and privacy risks is common practice for businesses and shouldn’t necessarily preclude the use of tools shown to provide benefits to users and businesses. “Enterprises face challenges to balance user privacy, user productivity, internal risk management, surveillance, and compliance,” he said. “That said, they should also consider what aggregate individual productivity gains there can be from tools like Recall and Copilot.”
Others, however, warned that businesses should avoid using the feature at all.
“While the ability to search your usage history can provide a time saving and production increase, I advise the risk to small businesses to use this feature is too great,” said McKee at SonicWall.
“First and foremost: if you can, don’t enable it,” said Forrester’s Pollard. “I would want it eliminated via group policy if available. If the feature is activated at any point, I would also want telemetry informing me it’s activated so that I can figure out if a user intended to activate it or if an adversary did [so] as part of their data gathering efforts.”
According to Microsoft’s admin page, those that don’t want to use Recall can disable it with the “Turn off saving snapshots for Windows” policy; doing so will also delete any snapshots already saved on the device.
“For enterprise customers, IT administrators can disable automatically saving snapshots using group policy or mobile device management policy,” Microsoft said on its support site.
The Recall feature is in preview, so changes could be made before it is generally available.
Lam said there may be ways Microsoft could improve the feature and reduce concerns around security and privacy. Recall could, for instance, “forget” more of the actions it has recorded, he suggested. “Can Recall limit its memories to a shorter time or reduced scope? What it may lose in accuracy it gains in user trust,” he said.
The AI capabilities in Windows might also improve to the point where it’s possible to classify data recorded by Recall more effectively, he said. Windows Copilot could also provide “enforced guidance,” anticipating and prompting users when screen recording should be stopped entirely.
For now, it’s hard to see how the feature can be securely used, said Pollard. “This feature is a risk in its entirety, and I can’t imagine any security or privacy controls making me comfortable with having it activated on a system I use,” he said.
Old PC, new PC. It’s great to get a new computer, but it’s not so great to realize that all your stuff is on the old one.
There are several ways to transfer your old computer’s data to your new PC. They fall into two main camps: transferring via cloud storage and transferring locally.
Tip: Before transferring all your data to your new PC, consider going through all your files, folders, and emails and weeding out the cruft. There’s a good chance you’ve got some ancient files and emails you no longer need. Is it really that important to keep all the 10-year-old presentations you created for a company you worked for two jobs back? Cleaning out your old data will make transferring your data to a new PC go more quickly, and in the future you won’t have to sift through old clutter to find the files you need.
Transfer files via cloud storage
The best and easiest way to transfer files is to use a cloud storage service as the waystation. Cloud storage works whether you are moving from a Windows 10 PC to a Windows 11 one, or from one Windows 11 PC to another. It even works if you are moving from a Macintosh to a Windows PC. Our article “The best way to transfer files to a new Windows PC or Mac” explains the ins and outs of migrating to a new computer via the cloud.
Transfer files locally to a new PC
That said, you may not be able to use the cloud to transfer your files — for instance, if the data-usage costs would be too high or you are not connected to the internet, or if your IT department won’t let you install the cloud account on both the old and new PCs.
And you might want to transfer more than just files from your old computer to your new one. This story includes methods for migrating files and apps, as well as browser bookmarks; one method can transfer some system settings as well.
Happily, most methods of transferring files locally from an old computer to a new Windows PC work whether you’re moving from a Windows PC to a Windows PC or from a Mac to a Windows PC.
You can connect an external hard drive, SD card, or thumb drive to your old PC, copy your files to it, then eject that device from the old computer, plug it into the new PC and copy the files to that new PC. The trick here (besides having enough storage capacity on your transfer drive) is to have your files and folders organized well enough so you get them all.
We recommend that you use the same folder organization on your new PC as on your old computer, at least to start. Once your migration is complete, you should consider storing your files on the cloud for easier access, as the article “The best way to transfer files to a new Windows PC or Mac” explains.
Tip: If you are transferring files from a Mac to a PC, the external hard drive must be formatted as MS-DOS, not NTFS or APFS. SD cards and thumb drives use the same FAT32 format on both macOS and Windows, so if your files fit on those storage devices, that’s often easier than using a hard drive.
Note: Digitally rights-managed files like purchased music usually won’t work once copied. The best way to transfer these is to re-download them from the service where you bought them. Such re-downloads are typically free.
As for email, if you use a cloud-based mail services such as Gmail or the cloud-based version of Outlook, you don’t need to transfer any mail files. However, if you use client-based email software (like the client version of Outlook), you’ve got some work ahead of you.
Direct file transfer will not move your locally stored email files to the new PC. Windows stores these files in fairly arcane places, and copying them to a new PC often doesn’t work because of how they are tied to the email application’s OS settings. We recommend you make sure all your emails are stored in your email server so they can just sync to the email client on your new PC. The Microsoft Outlook client supports several servers, not just Microsoft’s Exchange and Microsoft 365 typically used in business.
Note: IT retention policies may limit how far back emails are stored on the server, so you may have local emails you can’t transfer that way. In that case, Microsoft Outlook does let you import the local PST files to a Windows PC from the Outlook app on another Windows PC or Mac; Microsoft has provided export instructions and separate import instructions.
Different client versions of Outlook have different maximum size limits for .PST files that can be transferred from one computer to another. So if you’re planning move .PST files, read this Microsoft article to find out those limits and get advice on ways you might be able to reduce the size of .PST files before trying to transfer them.
Local contacts and calendar entries likewise are very difficult to directly transfer from one computer to another, and it is best to make sure they are stored on a server, such as Exchange, Microsoft 365, Google Workspace/Gmail/Google Calendar, or iCloud, so they will sync to your contacts and calendar apps on your new PC. Your contacts and calendar apps may have an export feature that you can try. (You can often export individual contacts as a VCF file, for example.) These days, few contacts and calendar apps are not server-based, so chances are very high your contacts and calendar entries are stored somewhere they can be synced from into Outlook.
Transfer via a File History backup
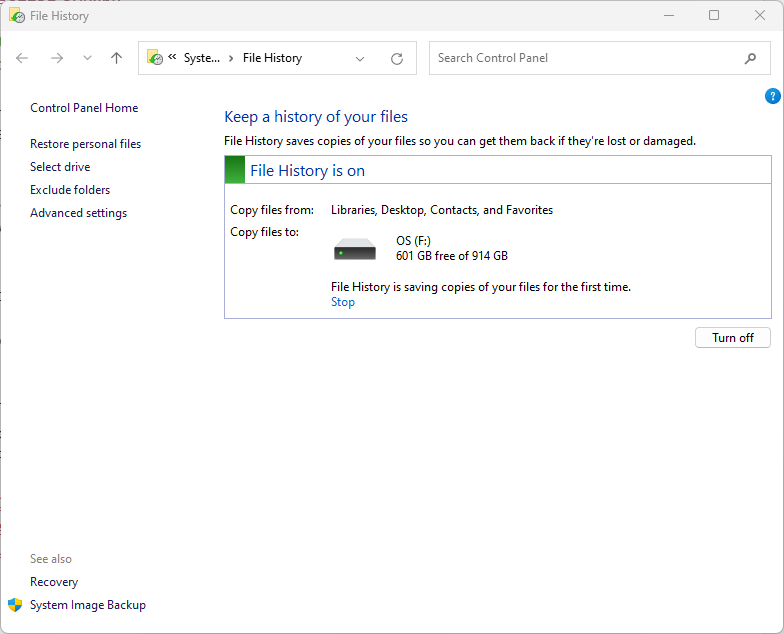
Windows 10 and 11 have a built-in backup utility that lets you restore a PC’s folder and files — but not settings or applications. You can use the Windows backup feature to restore files from an old PC to a new one. Windows calls this facility File History.
To use File History in Windows 10 or 11, type file history into the Windows search bar and click File History. That launches File History in Control Panel. You’ll see any external drives attached to your PC. Select the drive you want to use and click Turn on. Your files will be copied to the drive.
Using File History from Control Panel in Windows 11.
IDG
To exclude folders from the backup, select Exclude folders, click Add, and choose the folders you want to exclude.
To copy the backed up files to your new PC, plug the drive into it, repeat the above steps, and click Restore personal files.
One of the simplest ways to move files from your old PC to a new one is to use a USB data-transfer cable. You can’t use just any USB cable; it needs to be one specially designed to transfer data. When you plug the cables in, they often automatically install the drivers they need. They also come with file-transfer software that tends to be bare-bones but does the trick.
If you’d like, you can ditch cables completely, and move your files from your old PC to your new PC via Wi-Fi or a LAN. To do it, the PC with your files and the PC to which you want to transfer them need to be on the same Wi-Fi or Ethernet network.
To do it, you need to turn on network discovery and file sharing on both the PCs. In Windows 11, select Settings > Network & Internet > Advanced network settings > Advanced sharing settings, and turn on the toggles for Network Discovery and File and printer sharing.
In Windows 10, select Settings > Network & Internet > Network and Sharing Center. That will launch the Control Panel. In Control Panel, select Change advanced sharing settings from the right side of the screen, and from the screen that appears, in the Network Discovery section, select Turn on network discovery, and in the File and Printer sharing section, select Turn on file and printer sharing.
You can now drag and drop files and folders from your old PC to your new one using Windows Explorer. Click Network in File Explorer, find the new PC to which you want to transfer files and folders, and copy them to it.
Note that transferring files this way can be flaky — you may have problems with your PCs showing up on the network. Setting it up takes only a few minutes, though, and if it doesn’t work you can always use another method in this story to transfer the files. (For troubleshooting help, you may want to use the advice in PCWorld’s article “Windows 11: How to set up a local network.”)
Transfer via file-transfer software
If you want more hand-holding in your file transfer, you can buy and use a utility like Laplink’s $60 PCmover Professional, which has been around for decades. It works over your network (either Wi-Fi or Ethernet) or via Laplink’s Ethernet or USB cables (these cost extra). It lets you choose which files and folders to transfer, and will transfer your settings, bookmarks, and applications too. You can migrate from old Windows versions to later Windows versions, as well as between the same versions. (One exception: you cannot migrate from Windows XP to Windows XP.)
Note: You need administrator privileges in Windows to use all of PCmover’s capabilities.
Before you transfer any applications via a utility like PCmover, sign out of or deactivate any apps on your old computer. Most software these days is tied to an online account that limits the number of active installations or has digital rights management to prevent piracy via copying. You don’t want the transfer to be seen as a piracy attempt or as an additional installation that counts against any limit you may have.
Another option is EhlerTech’s USMTGUI, a graphical front end to Microsoft’s command-line User State Migration Tool, which works with Windows 7 through 10. The Pro version adds support for migrating from (but not to) Windows XP and Vista. USMTGUI (like USMT) transfers only settings and associated data like emails, not applications. The home version pricing starts at $10, and the corporate license pricing starts at $200.
Transfer and set up apps on your new PC
Regardless of the transfer method you use, you almost certainly will have apps to reinstall, depending on what IT did for you in preparing your new computer. (PCmover Professional will transfer most apps; its documentation describes its limitations.)
On your new PC, re-download the apps you need and sign in as required. You’ll find some apps on the Microsoft Store in Windows 10 or 11, while others you’ll need to download from the software vendor’s website. If you’re moving from macOS to Windows, some apps won’t be available for installation in Windows, but most macOS business apps come in both versions and most software manufacturers (but not all!) let you use the same license on either platform.
In most cases, you’ll need to set up your applications’ preferences on the new computer, so set aside the time to do that.
Transfer browser bookmarks to your new PC
You also will want to transfer your bookmarks from your old computer’s browser to your new computer’s browser. There are three methods: direct syncing between the same browser, syncing between macOS’s Safari and certain Windows browsers, and exporting a browser’s bookmark files to import into a different browser. The first two methods keep the browsers in sync, whereas the third method is a manual approach for when you are moving to a new computer (or browser) and won’t use the old computer (or browser) anymore.
Chrome, Firefox, and Edge all sync bookmarks across all your devices if they are all signed into the same account. Just enable syncing in each browser on each device you use. To be clear, you can sync only to the same browser, such as from Chrome to Chrome.
Apple’s Safari is not available for Windows (or Android), but you can sync between Apple’s Safari and a supported Windows browser (Chrome, Firefox, or Internet Explorer) if iCloud is installed in Windows and signed in to the same account as the Mac or iOS device running Safari. Note: iCloud syncing is not available for education users with managed Apple IDs.
For situations where your browser is not signed into the same account as your old computer, the major browsers all have a facility to export and import bookmarks via files:
Google Chrome: To export bookmarks, click the vertical three-dot icon at the top right of your browser window, then select Bookmarks and lists > Bookmark Manager from the menu that appears. Click the three-dot icon to the right of the search bar and select Export bookmarks. To import bookmarks, follow the same procedure but choose Import bookmarks instead of Export Bookmarks.
Mozilla Firefox: To export bookmarks, click the Menu button (three horizontal lines) on the top right of the screen, then select Bookmarks and click Manage bookmarks at the bottom of the screen. Select Import and Backup from the top of the screen that appears and choose Export Bookmarks to HTML. To import bookmarks, follow the same procedure but choose Import Bookmarks from HTML instead of Export Bookmarks to HTML.
Apple Safari: To export bookmarks from this macOS browser for import into a Windows browser, choose the File menu > Bookmarks > Export.
Microsoft Edge (Chromium version): In both Windows and macOS, click the Favorites button (the star icon), then choose Manage favorites to open the Favorites window, select the desired bookmarks folder to export, click the horizontal three-dot icon at the top right of the browser window, and choose Export favorites. To import bookmarks, follow the same procedure but choose Import favorites instead of Export favorites.
Microsoft Edge (legacy version): To export bookmarks from this discontinued browser that was pre-installed in Windows 10 versions prior to 20H2, click the three-dot icon to open the General window, click Import or Export to open the Import export window, scroll down until you see Export your favorites and reading list to an HTML file, select Favorites to export your bookmarks, then click Export to file. To import bookmarks, follow the same procedure but click Import from file instead of Export to file.
Internet Explorer: To export bookmarks from this discontinued Windows browser, click the Favorites button (star icon), choose Import and Export from its menu, select the Export to a file option, click Next >, select Favorites to export bookmarks (and optionally Feed and Cookies to export them), click Next >, choose the bookmarks folder to export, click Next >, set the export location, and click Export. To import bookmarks, follow the same procedure but select the Import from a file.
What to do after transferring your files and apps to the new PC
When everything is transferred, be sure to take these steps to protect your data:
Sign out of all your accounts on the old computer. This includes Microsoft, Google, iCloud, iTunes, browser sync, shopping, cloud storage accounts, and others. You don’t want to exceed any maximums on computers that can be signed in, and you don’t want the next owner to be able to use your accounts, especially any that may connect to credit and debit cards.
Consider wiping/reformatting the old computer, but check with IT first, in case they need to keep it as is for some period of time for regulatory or HR policy reasons.
When everything is transferred, be sure to sign out of all your accounts, such as Microsoft, Google, iCloud, iTunes, browser sync, shopping, and cloud storage accounts, on the old computer. You don’t want to exceed any maximums on computers that can be signed in, and you don’t want the next owner to be able to use your accounts, especially any that may connect to credit and debit cards. You might even consider wiping/reformatting the old computer, but check with IT first, in case they need to keep it as is for some period of time for regulatory or HR policy reasons.
This article was originally published in November 2020 and updated in May 2024.
It may or may not have hit you yet, but brace yourself: It’s coming.
As we speak, Google’s in the midst of bringing its Gemini-powered generative-AI obsession into its most prominent and powerful product — and that’s search. Soon, anytime you search for something within Google, whether on your phone or on a computer and whether at the office or on the go, you’ll get AI-powered answers in place of the familiar blue links.
You can see the new incoming setup for yourself in this demo video, and it should show up in your Google search results soon — like it or not:
Before you shed too many tears, though, take note: That may be the default search experience for most people moving forward — but you aren’t most people. You’re a smart and thoughtful Homo sapien who’s reading this column and capable of taking matters into your own hands.
And with about 60 seconds of effort, you can give yourself a simpler, smarter, and more efficient search setup that lets you find what you want from sources you trust without all the greasy AI gravy. It’s a return to a purer-seeming, more straightforward form of search — something closer to the web-wading prowess Google gave us originally, way back in its early days, before all the other stuff started creeping into the mix.
With the way things are shaping up around Gemini and other such large-language model AI systems right now, it may be the most important and impactful upgrade you make all year.
Ready?
Google’s Gemini-free web search option
So here’s the secret ingredient that makes this whole thing possible: Amidst all the AI hullabaloo coming out of Google’ grand I/O gala last week, the company quietly rolled out an out-of-sight feature that seems like the most significant search improvement of all.
It’s a new web-only mode for Google Search results that lets you eliminate all AI elements, knowledge panels, and also — for the moment, at least — ads from the page and focus only on the most relevant results from the web for your query. A novel concept, no?!
Google didn’t make any big announcements about the option, and you’d really have to know it’s there to find it. But it’s an incredible new resource to tap into, and with some super-simple setup, you can bring it up to the surface and make it readily available at your fingertips for hassle-free ongoing use.
The option is typically buried within the “More” menu that pops up alongside “Images,” “Videos,” and other such options at the top of Google Search results — right beneath the search box at the top of the screen. If you want to dig it up and try it out to see how it works, you can do so there without any commitment or lasting changes.
Here, meanwhile, is how to make that option your default search setup — no matter what kind of device you’re working on at any given moment:
The web-only Google search switch for Android
First, on the Android front, you curiously can’t set just anything to be your default search engine in most browsers right off the bat — so we’ve first gotta show your browser such a search setup in action and let it know that it exists.
Luckily, a crafty and generous web-warping internet citizen took it uponst themselves to create a page that makes this not only possible but also almost effortless to pull off:
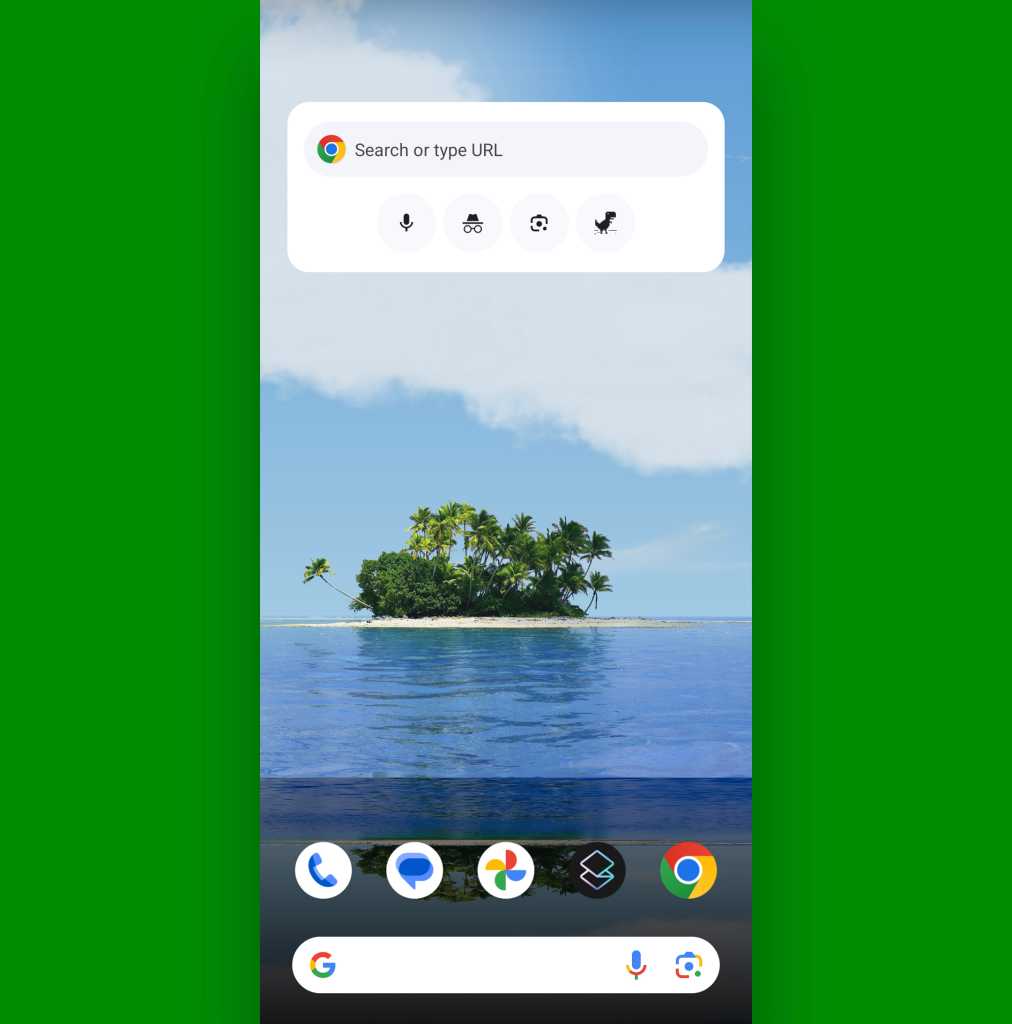
First, open this link within your favorite Android browser. (My instructions from here on out will be specific to Chrome, since that’s the de facto default Android web browser and what the vast majority of humans rely on, but most other Android browsers should offer similar — if occasionally slightly shifted around and reworded — options of their own.)
Next, open up a new tab and search for anything at all. (I’d suggest “smiling salamanders,” but you do you.)
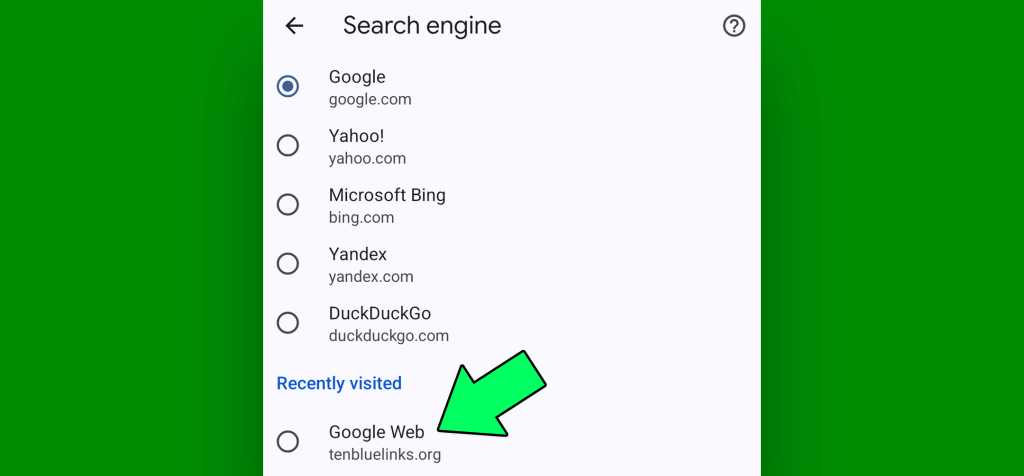
Once you’ve done that, tap the three-dot menu icon in the browser’s upper-right corner and select “Settings” followed by “Search Engine.”
Look for the newly added “Google Web” option beneath the “Recently visited” heading. Tap it to select it, then back your way out of that menu.
That little added option makes all the difference in the world.
JR Raphael, IDG
And hey, how ’bout that? You’ve just given yourself direct access to web-only results by default for all of your browser-made searches. Just type whatever you want to find directly into the browser’s address bar, and you’ll be golden.
Search results from the web. What a concept!
JR Raphael, IDG
It’s worth noting that this change won’t affect searches started in other places — like within the Google Android app or any Google-associated search boxes on your home screen, for example. But you can always add a Chrome-specific search box (or a search box connected to any other browser you’re using) onto your home screen for even easier on-demand access:
Press and hold a finger onto any blank space on your home screen and find the option to add a new widget.
Scroll through the list of choices until you see “Chrome” (or, alternatively, another browser — if you’d rather).
Tap that and look for the browser’s search widget. With Chrome, you can choose from either a traditional search bar or a series of icons that includes a browser-based search as well as a voice search, an incognito tab search, and even a visual search via Google Lens.
Tap or press and hold the widget to finish adding it onto your home screen.
The Chrome Android widget makes it exceptionally easy to start a web-only search within Google.
JR Raphael, IDG
Now, any of those options will take you directly into your browser with your newly refined web-only results for whatever you’re searching.
Not bad, right?! And it’s even easier to bring this newfound nugget of search sanity front and center within the desktop domain.
The web-only Google search switch for desktop computers
No matter what kind of computer you’re using — Windows, ChromeOS, Linux, even (gasp!) a Mac (if you must) — you can make Google’s new web-only search mode exceptionally accessible in your desktop browser via a custom Chrome address bar action.
The same sort of thing is possible in most other browsers, too, so if you aren’t using Chrome, poke around a bit — and you should find a similar equivalent.
Basically, the idea — as first surfaced by Tedium’s Ernie Smith — is that you create your own custom search engine within Chrome’s settings, using a specially formatted URL that leads you to the Google web-only search setup. You can then either summon that command by typing a series of letters into the browser’s address bar or you can go a step further and set it as the default search engine for all of your browser-based searching escapades.
Either way, it takes surprisingly little legwork to accomplish:
First, type chrome:settings into Chrome’s address bar to pull up the browser’s settings.
Click “Search engine” in the main left-of-screen menu, then click “Manage search engines and site search.”
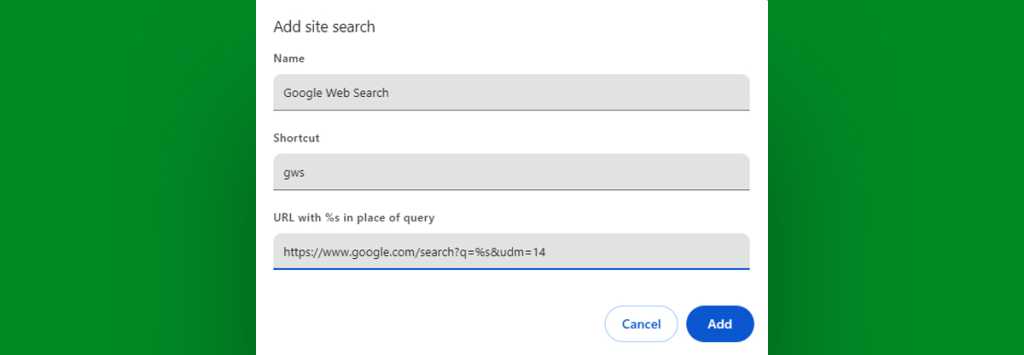
See the section in the screen’s main area called “Site search”? Click the Add button alongside it.
Now, in the box that comes up…
Type Google Web Search into the “Name” field.
Type gws into the “Shortcut” field.
And in the “URL” field, paste in the following string of text:
https://www.google.com/search?q=%s&udm=14
This may look like a bunch of gibberish at the moment, but just you wait — just you wait.
JR Raphael, IDG
Now, click the Add button — and think about how you’d like this to work.
If you’d like to keep the standard (soon-to-be AI-powered) Google Search approach as your default, just remember the shortcut gws. You can now type those three letters into your browser’s address bar and then hit the Tab key anytime to initiate a web-only search without all the other elements.
If you’d like to make the web-only search your browser-wide default — so that any terms you type into the address bar automatically get sent into that web-only results format…
Find your newly created shortcut within the same “Site search” section of the Chrome settings that we were just looking at. (You might have to click an “Additional sites” link at the bottom of that section to see it.)
Click the three-dot menu icon to the right of the shortcut’s line.
And click “Make default” in the menu that pops up.
The easy-to-miss command that changes everything.
JR Raphael, IDG
All that’s left is to pat yourself on the back and get yourself a cookie and/or cobbler: You’ve successfully eliminated Gemini’s inconsistently inaccurate answers from your search results and injected a whole slew of extra sanity into your information-finding workflow.
Now, that’s what I call progress.
Treat yourself to a smorgasbord of smart shortcut knowledge with my free Android Shortcut Supercourse. You’ll learn tons of time-saving tricks for your phone!
Nothing lives forever, and researchers have confirmed that web pages are no exception. They pop into existence at one moment in time and have a habit of disappearing with an abrupt “404 not found” at an unknown point in the future.
The rate at which this happens has a name: “digital decay”, or “link rot”. According to an analysis by the Pew Research Center, When Online Content Disappears, we can even put some numbers on the phenomenon.
Looking at a random sample of web pages that existed in 2013, the researchers found that by 2023, 38% had disappeared. If it doesn’t sound surprising that nearly four in ten web pages from 2013 would have disappeared a decade later, they did the same analysis for pages that appeared in 2023 itself, finding that a surprising 8% disappeared by the year end.
But what matters is not simply how many web pages have disappeared but where they disappeared from. On that score, 23% of news pages and 21% of pages on US government sites contained at least one broken link.
The most interesting barometer of all for link rot is Wikipedia, a site which depends heavily on referenced links to external information sources.
Despite the importance of references, the researchers found that at least one link was broken on 54% of a sample 50,000 English language Wikipedia entries. From the total of one million references on those pages, 11% of the links were no longer accessible.
Disappearing tweets
And it’s not just links. Looking at that other cultural reference point, “tweets” on the X (formerly Twitter) platform, a similar pattern was evident. From a representative sample of 5 million tweets posted between 8 March and 27 April 2023, the team found that by 15 June 18% had disappeared. And that figure could get a lot higher if the company ever stops redirecting URLs from its historic twitter.com domain name.
Some languages were more affected by disappearing tweets than others, with the rate for English language tweets being 20% and for those in Arabic and Turkish an extraordinary 42% and 49%, respectively.
Pew is not the first to look into the issue. In 2021, an analysis by the Harvard Law School of 2,283,445 links inside articles on New York Times articles found that of the 72% that were deep links (i.e., pointing to a specific article rather than a homepage), 25% were inaccessible.
As a website that’s been in existence since 1996, The New York Times is a good measure of long-term link rot. Not surprisingly, the further back in time you went, the more rot was evident, with 72% of links dating to 1998 and 42% from 2008 no longer accessible.
This study also looked at content drift, that is the extent to which a page is accessible but has changed over time, sometimes dramatically, from its original form. On that score, 13% of a sample 4,500 pages published in the New York Times had drifted significantly since they’d first been published.
Where is IT going wrong?
Does any of this matter? One could argue that web pages disappearing or changing is inevitable even if not many people notice or care.
While the Pew researchers offer no judgement, the authors of the Harvard Law School study point out the problems link rot leaves in its wake:
“The fragility of the web poses an issue for any area of work or interest that is reliant on written records. […] More fundamentally, it leaves articles from decades past as shells of their former selves, cut off from their original sourcing and context.”
According to Mark Stockley, an experienced content management systems (CMS) and web admin who now works as a cybersecurity evangelist for security company Malwarebytes, while some link loss was inevitable, the scale of the issue suggested deeper administrative failures.
“People seem to be more ambivalent about losing pages than they used to be. When I first started working on the web, losing a page, or at least a URL, was anathema. If you didn’t need a page any more you at least replaced it with a redirect to a suitable alternative, to ensure there were no dead ends,” said Stockley.
“What’s baffling is when CMSs don’t pick up the slack. While some CMSs will catch mistakes and backfill URL changes with redirects automatically, there are others that, inexplicably, don’t. It’s an obvious and easy way to prevent a particular kind of link rot, and it’s baffling that it exists in 2024,” he said.
Alternatively, if the CMS doesn’t include a link checking facility, admins can also deploy link checking tools that will crawl a site to find broken links.
For CMS admins, spotting and correcting broken links should be a defined process not an afterthought.
Anyone who wants more detail on the methodology behind When Online Content Disappears can follow this link (PDF).
Nothing lives forever, and researchers have confirmed that web pages are no exception. They pop into existence at one moment in time and have a habit of disappearing with an abrupt “404 not found” at an unknown point in the future.
The rate at which this happens has a name: “digital decay”, or “link rot”. According to an analysis by the Pew Research Center, When Online Content Disappears, we can even put some numbers on the phenomenon.
Looking at a random sample of web pages that existed in 2013, the researchers found that by 2023, 38% had disappeared. If it doesn’t sound surprising that nearly four in ten web pages from 2013 would have disappeared a decade later, they did the same analysis for pages that appeared in 2023 itself, finding that a surprising 8% disappeared by the year end.
But what matters is not simply how many web pages have disappeared but where they disappeared from. On that score, 23% of news pages and 21% of pages on US government sites contained at least one broken link.
The most interesting barometer of all for link rot is Wikipedia, a site which depends heavily on referenced links to external information sources.
Despite the importance of references, the researchers found that at least one link was broken on 54% of a sample 50,000 English language Wikipedia entries. From the total of one million references on those pages, 11% of the links were no longer accessible.
Disappearing tweets
And it’s not just links. Looking at that other cultural reference point, “tweets” on the X (formerly Twitter) platform, a similar pattern was evident. From a representative sample of 5 million tweets posted between 8 March and 27 April 2023, the team found that by 15 June 18% had disappeared. And that figure could get a lot higher if the company ever stops redirecting URLs from its historic twitter.com domain name.
Some languages were more affected by disappearing tweets than others, with the rate for English language tweets being 20% and for those in Arabic and Turkish an extraordinary 42% and 49%, respectively.
Pew is not the first to look into the issue. In 2021, an analysis by the Harvard Law School of 2,283,445 links inside articles on New York Times articles found that of the 72% that were deep links (i.e., pointing to a specific article rather than a homepage), 25% were inaccessible.
As a website that’s been in existence since 1996, The New York Times is a good measure of long-term link rot. Not surprisingly, the further back in time you went, the more rot was evident, with 72% of links dating to 1998 and 42% from 2008 no longer accessible.
This study also looked at content drift, that is the extent to which a page is accessible but has changed over time, sometimes dramatically, from its original form. On that score, 13% of a sample 4,500 pages published in the New York Times had drifted significantly since they’d first been published.
Where is IT going wrong?
Does any of this matter? One could argue that web pages disappearing or changing is inevitable even if not many people notice or care.
While the Pew researchers offer no judgement, the authors of the Harvard Law School study point out the problems link rot leaves in its wake:
“The fragility of the web poses an issue for any area of work or interest that is reliant on written records. […] More fundamentally, it leaves articles from decades past as shells of their former selves, cut off from their original sourcing and context.”
According to Mark Stockley, an experienced content management systems (CMS) and web admin who now works as a cybersecurity evangelist for security company Malwarebytes, while some link loss was inevitable, the scale of the issue suggested deeper administrative failures.
“People seem to be more ambivalent about losing pages than they used to be. When I first started working on the web, losing a page, or at least a URL, was anathema. If you didn’t need a page any more you at least replaced it with a redirect to a suitable alternative, to ensure there were no dead ends,” said Stockley.
“What’s baffling is when CMSs don’t pick up the slack. While some CMSs will catch mistakes and backfill URL changes with redirects automatically, there are others that, inexplicably, don’t. It’s an obvious and easy way to prevent a particular kind of link rot, and it’s baffling that it exists in 2024,” he said.
Alternatively, if the CMS doesn’t include a link checking facility, admins can also deploy link checking tools that will crawl a site to find broken links.
For CMS admins, spotting and correcting broken links should be a defined process not an afterthought.
Anyone who wants more detail on the methodology behind When Online Content Disappears can follow this link (PDF).